

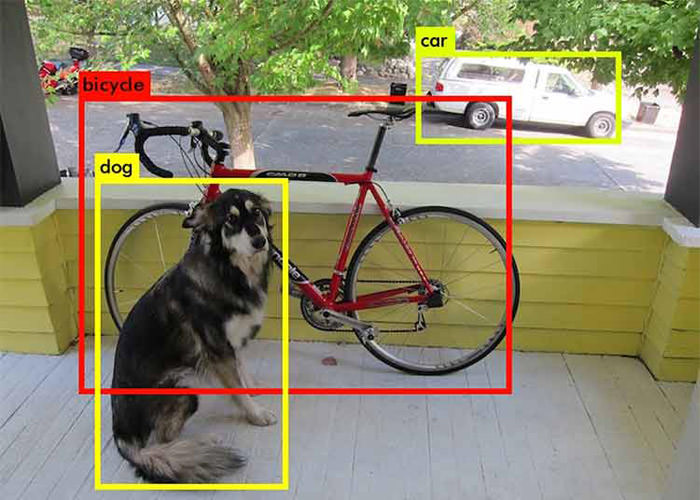
بحث تشخیص اشیا در تصویر یکی از زیرمجموعههای بینایی ماشین است. تشخیص اشیا یک روش خودکار برای تعیین و تشخیص اشیا در یک عکس، با در نظر داشتن پسزمینه است. کمی پیچیده شد. اجازه دهید با یک مثال موضوع را بهتر توضیح دهیم. در بالا یک عکس مشاهده میکنید که در پسزمینه خود چند جسم دارد. این اجسام شامل یک سگ، یک دوچرخه و یک ماشین هستند. در سیستم تشخیص اشیا، دور هر جسم یک کادر قرار میگیرد و آن را احاطه میکند. هر کادر با توجه به جسم داخل آن نامگذاری شده و در دستهی مرتبط با خود قرار میگیرد. یادگیری عمیق، مانند مدلهای دیگر بینایی ماشین، روش نوینی برای اجرای فرآیند شناسایی اجسام است. در این مقاله از فنولوژی، موضوع تشخیص اشیا با یادگیری عمیق را بیشتر بررسی میکنیم.
تشخیص اشیا در تصویر چگونه کار میکند؟
یکی از مشکلات اساسی سیستم تشخیص اشیا این است که تعداد اجسام موجود در پسزمینهی عکسها با هم متفاوت است. برای درک نحوهی کار این سیستم، ابتدا مشکل را فقط به یک جسم در عکس محدود میکنیم. وقتی در هر عکس فقط یک جسم موجود باشد، پیدا کردن مکان مناسب برای کادر و دستهبندی آن کار سادهای است. کادر احاطهکنندهی ما متشکل از ۴ شماره است. بنابراین تعیین موقعیت کادر، مربوط به بحث رگرسیون است. پس، مشخص کردن دستهی کادر، مربوط به بحث طبقهبندی است. شبکه عصبی پیچیده (CNN) که در عکس زیر نشان داده شده، برای اجرای رگرسیون و طبقهبندی روی شی احاطه شده، راه حل ارائه میدهد. سیستم شناسایی اجسام هم مانند بقیهی زیرمجموعههای بینایی ماشین (مانند سیستمهای تشخیص عکس، شناسایی نقاط کلیدی و بخشبندی معنایی که در ماشینهای خودران هم کاربرد دارد) با تعداد اهداف مشخصی سر و کار دارد. برای انجام فرآیند، میتوان هر هدف را به صورت چند مورد مربوط به رگرسیون و طبقهبندی تعریف کرد.
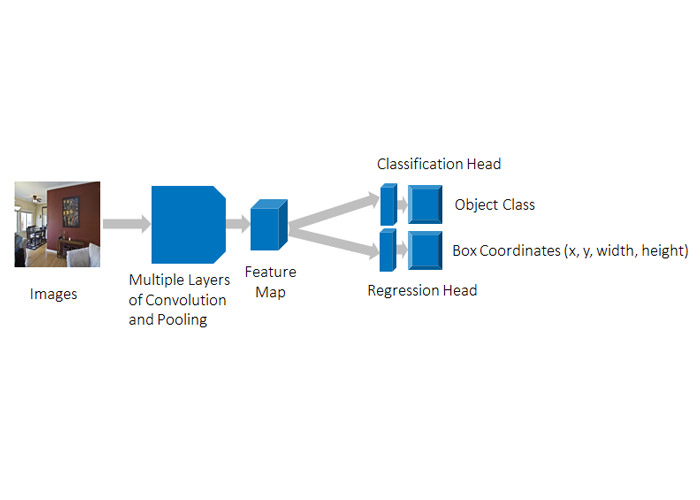
تشخیص اشیا به شکل پیچیده
یک شناساگر اشیا واقعی باید بتواند با تعداد نامحدودی جسم در یک عکس کار کند. این تعداد نامحدود جسم در عکسها متفاوت است. شبکهی عصبی پیچیدهای که در عکس بالا نشان داده شده، نمیتواند با بیش از یک جسم کار کند. ما میتوانیم چند مستطیل با اندازهها و مکانهای مختلف در نظر بگیریم و از نوع دیگری از شبکهی عصبی پیچیده فقط برای طبقهبندی آنها استفاده کنیم. معمولا به این کادرهای مستطیلی پنجره گفته میشود. برای جامع و کامل بودن کار، این پنجرهها باید تمام نقاط عکس را پوشش دهند و در تمام اندازههای ممکن در دسترس باشند. هر پنجره جداگانه بررسی میشود که مشخص شود داخل آن جسمی وجود دارد یا نه. اگر جسمی وجود داشت، در دسته مناسب قرار داده میشود.
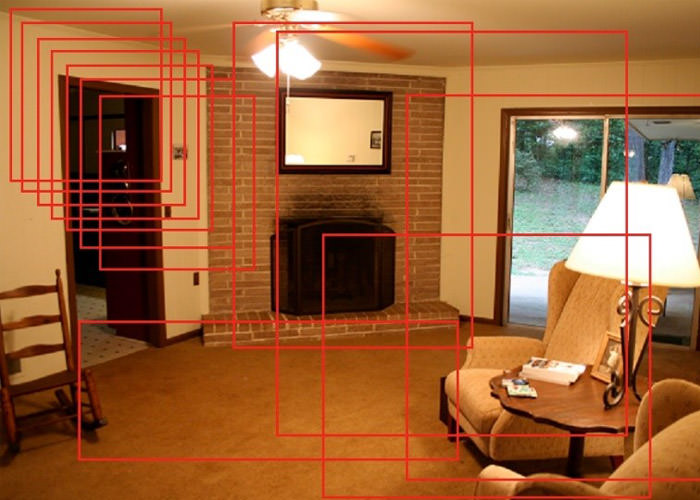
در عکس بالا تعدادی از پنجرههایی که در این روش به کار برده میشوند را مشاهده میکنید. در این عکس تنها تعداد کمی پنجره نمایش داده شده است. با توجه به تعداد فوقالعاده زیاد پنجرههایی که باید بررسی شود، این روش کاربردی نیست.
راههای کارآمد برای تشخیص اشیا (object detection) در پنجرهها
آیا میتوانیم تنها با بررسی چند پنجره فرآیند تشخیص اشیا را انجام دهیم؟ بله می توانیم. دو روش برای پیدا کردن این پنجرههای خاص وجود دارد. این دو روش از دو دستهی متفاوت از الگوریتم های تشخیص شی استفاده میکنند.
دستهی اول الگوریتم های تشخیص شی
الگوریتمهای دستهی اول، ابتدا بررسی منطقهای انجام میدهند. یعنی مناطقی که احتمال وجود اشیا در آنها بیشتر است انتخاب میشوند. این انتخاب یا توسط روشهای قدیمی بینایی ماشین (مثل جستجوی انتخابی) انجام میشود، یا توسط RPN .RPN بر مبنای یادگیری عمیق کار میکند. پس از به دست آمدن گروهی کوچک از پنجرهها، تشخیص اشیا به کمک معادلههای تشکیل شده از چند مدل رگرسیون و چند مدل طبقهبندی، انجام میشود. این کار شامل الگوریتمهایی از قبیل Faster R-CN ،R_FCN و FPN-FRCN است. الگوریتمهایی که در این دسته قرار دارند معمولا «روش دو مرحلهای» نامیده میشوند. این الگوریتمها دقیقتر اما کندتر از روش تک مرحلهای هستند.
دستهی دوم الگوریتم های تشخیص شی
الگوریتمهای دستهی دوم تنها در مکانها و اندازههای مشخص دنبال اجسام میگردند. این مکانها و اندازهها به گونهی استراتژیکی انتخاب میشوند تا بیشتر حالات ممکن را پوشش دهند. الگوریتمهای این گروه معمولا عکس را به چند بخش با اندازهی مشخص تقسیم میکنند. سپس در نظر میگیرند که در هر بخش، تعداد مشخصی اجسام با اشکال و اندازههای از پیش تعیینشده وجود دارد. الگوریتمهای این دسته «روش تک مرحلهای» نامیده میشوند. الگوریتمهای YOLO ،SSD و RetinaNet از مثالهای این دسته هستند. الگوریتمهای این دسته معمولا سریعتر عمل میکنند ولی دقت کمتری دارند. اغلب برای استفاده از این الگوریتمها، از برنامههای دارای ویژگی شناسایی لحظهای استفاده میکنند.
در ادامه دو روش معمول برای شناسایی اجسام را بررسی می کنیم.

۱-الگوریتم YOLO در تشخیص اشیا (object detection)
الگوریتم YOLO نمایندهی روش تک مرحلهای است. مراحل کار این الگوریتم بدین صورت است:
۱. عکس اصلی را به چندین بخش مساوی تقسیم میکند.
۲. در هر بخش، تعدادی کادر با اشکال از پیش تعیین شده به محوریت مرکز آن بخش در نظر میگیرد. سپس وجود یا عدم وجود جسم در کادر و دستهی آن کادر مشخص میشود.
۳. در آخر کادرهایی که احتمال وجود جسم در آنها بیشتر است و با ردهی خود خوانایی بیشتری دارند انتخاب میشوند. دستهای که یک جسم در آن طبقهبندی میشود، ردهای است که احتمال تطبیق آن با جسم بیشتر است.
کادرهای لنگر
به کادرها با شکلهای از پیش تعیین شده، کادرهای لنگر گفته میشود. این کادرها با استفاده از الگوریتمهایی با متغیر K تشکیل میشوند. کادرهای لنگر اطلاعات اولیه در مورد اندازه و شکل اجسام را جمعآوری میکنند. لنگرهای مختلف طراحی میشوند تا اجسام با شکلها و اندازههای متفاوت را شناسایی کنند. برای مثال در عکس زیر سه کادر لنگر در یک مکان به محوریت یک نقطه وجود دارند. کادر قرمز شخصی که در وسط ایستاده را شناسایی میکند. به عبارت دیگر الگوریتم، جسمی که اندازهاش تقریبا برابر با کادر لنگر است را تشخیص میدهد.

مکان و اندازهی کادر نهایی اغلب با کادر لنگر متفاوت است و کمی تغییرات روی کادر لنگر اعمال میشود. این تغییرات با استفاده از طرح کلی اجسام موجود در عکس محاسبه میشوند. طرح اجرایی الگوریتم YOLO در عکس زیر نمایش داده شده است. مرحلهی تشخیص این الگوریتم، دارای تعداد زیادی تنظیمکنندهی رگرسیون و طبقهبندی است. تعداد این تنظیمکنندهها وابسته به تعداد کادرهای لنگر است.
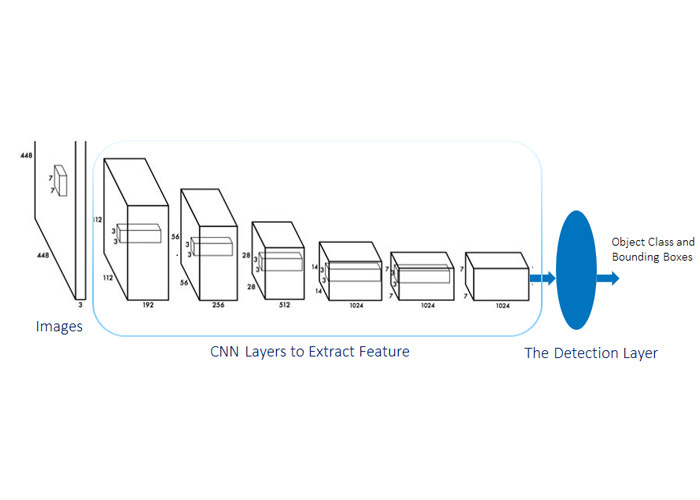
۲-الگوریتم Faster RCNN در شناسایی اجسام (object detection)
الگوریتم Faster RCNN، یک الگوریتم از روش دو مرحلهای است. با وجود اینکه در اسم این الگوریتم کلمهی Faster (سریعتر) به کار برده شده، از روش تک مرحلهای سریعتر نیست. این کلمه تنها نشاندهندهی این است که این الگوریتم از نسخههای پیشین خود یعنی الگوریتمهای RCNN و Fast RCNN سریعتر عمل میکند. دلیل این عملکرد سریعتر، اشتراکگذاری محاسبات انجام شده برای استخراج اشکال در تمام بخشها است (به این کار Rol گفته میشود).
بعد از به کارگیری چند لایه شبکهی عصبی پیچیده و محاسبهی طرح اجسام، چند پنجره تولید میشود که به احتمال زیاد در آنها جسم وجود دارد. سپس، الگوریتم، طرح اجسام را که از پیش محاسبه کرده بود در هر پنجره به کار میگیرد و اندازهی آن پنجره را مشخص میکند. همچنین الگوریتم همزمان دستهی جسم را به همراه یک کادر دقیقتر برای آن پیشبینی میکند.
تشکیل پنجره
یک مسئلهی مهم این است که چگونه این پنجرهها را ایجاد میشوند. این شبکه هم مانند الگوریتم YOLO از کادرهای لنگر استفاده میکند؛ اما، بر خلاف الگوریتم یولو، این کادرها بر اساس اطلاعات جمعآوری شده تشکیل نمیشوند. بلکه اندازه و شکل آنها تماما از پیش تعیین شده است. ممکن است این کادرهای متراکمتر، عکس را بپوشانند.
خلاصه
شناسایی اجسام یکی از کارهای دشوار در زمینهی بینایی ماشین است. بیشتر به این دلیل که تعداد اجسام در عکسها متفاوت است. کادرهای لنگر به منظور انتخاب کادرهای زیرمجموعه برای شناسایی اجسام طراحی شدند. لنگرها میتوانند با استفاده از اطلاعات جمعآوری شده ایجاد شوند یا کاملا از پیش تعیین شده باشند.
در روش تک مرحلهای، الگوریتمها با استفاده از کادرهای لنگر شناسایی اجسام را به صورت مستقیم انجام میدهند. در روش دو مرحلهای، الگوریتمها از لنگرها استفاده میکنند تا ابتدا منطقههای پیشنهادی را پیدا کرده و سپس کادرهای احاطه کننده و دستهی اجسام را تعیین کنند.
از لحاظ کاربردی الگوریتمهای تک مرحلهای مثل یولو بهتر هستند. با اینکه دقت کمتری دارند، ولی پیچیدگی محاسباتی که انجام میدهند بر اساس محدودیت و توان سختافزاری است. خطای آنها هم قابل چشمپوشی است؛ اما، اگر اولویت دقت زیاد است، روشهای دو مرحلهای بهتر هستند. در ویدیو زیر توضیحات بیشتری در مورد شناسایی اجسام و چگونگی آن، ارائه شده است.
منبع: SAS





سلام ببخشید توی خودرو های خودران چطور پردازش تصویر اتفاق میوفته چون اونجا سنسور لیدار (LIDAR) با فرمت خاصی اطلاعات میفرسته
ببخشید اون فرمت فایل چیه و چطور باید تبدیل بشه به فایل قابل فهم برای مرحله پردازش تصویر؟
ممنونم از جوابدهی شما.
آیا شما همچین پروژه ای رو انجام میدید؟
عالی بود