

تو این مقاله میخوایم با یه زبون خیلی ساده بهتون بگیم ساختمان داده دقیقا چی هست! فرض کنید در زمانی زندگی میکنید که هنوز موبایل اختراع نشده و مجبور هستین شمارههای تلفن خانههای اقوام و دوستان رو داخل یک دفترچه یادداشت کنید 🙂 عجب کار سمی! بعد حالا فرض کنید دوست و آشنا هم زیاد دارید و یه چند هزارتایی شماره داخل این دفترچه نوشتین. سم اصلی اون جایی خودنمایی میکنه که شما بخواین از بین این چند هزار تا شماره، شماره اصغر آقا رو پیدا کنی و بهش زنگ بزنی. خب اگه بدون هیچ نظم و ترتیبی شمارهها رو یادداشت کرده باشین، پیدا کردن شماره اصغر آقا تقریبا غیرممکنه. چه راه حلی به ذهنتون میرسه که این کار (یعنی پیدا کردن شماره)، راحتتر بشه؟ یه راهی که حتما به ذهنتون رسیده اینه که دفترچه رو به ترتیب حروف الفبا پر کنید و بعد موقع پیدا کردن شماره اصغر آقا، سراغ حرف الف برین و خیلی راحت شماره رو پیدا کنین. در ادامه علاوه بر آشنایی با Data Structure، با کاربردهای ساختمان داده و انواع اون بیشتر آشنا میشیم. اگه با برنامهنویسی آشنایی اولیه ندارین، حتما دوره آموزش پایتون فنولوژی رو ببینید!
کاربرد ساختمان داده در کامپیوتر
مثل همون مثال دفترچه تلفن که گفتیم، داخل کامپیوتر هم باید دادهها رو با نظم و ترتیب مناسبی جایدهی کنیم؛ اما چرا؟ میدونیم که کامپیوتر محدودیتهای آدم رو نداره. یعنی مثلا اگه هزار تا شماره تلفن و اسم هم بهش بدیم و بعدش یه اسمی رو سرچ کنیم، بلافاصله شماره رو به ما میده چون سرعت کامپیوتر خیلی خیلی بیشتر از آدمه. پس چرا نحوه جایدهی دادهها در کامپیوتر اهمیت داره؟
حق با شماست؛ انجام کار سادهای مثل جستوجو بین هزار تا آیتم برای کامپیوتر خیلی کار سادهای هست و نیاز به نظم دادن این دادهها نیست؛ اما بیایید یک معیار به دست بیاریم تا متوجه بشیم کامپیوتر در چه زمانی میتونه یک محاسبه خاص رو انجام بده. اگه ما یک پردازنده ۳GHz داشته باشیم، میشه گفت که این پردازنده در هر ثانیه میتونه ۳ میلیارد عملیات رو انجام بده (منظور ما از عملیات، انجام کارهای سادهای مثل جمع، تفریق، ضرب، تقسیم و مقایسه هست). خب حالا توی این مثال دفترچه تلفن، اگه ما ده هزار تا شماره تلفن داشته باشیم، در بدترین حالت (حالتی که شماره مطلوب ما آخرین شماره باشه)، نیاز هست ده هزار مقایسه انجام بشه. پردازنده ما این مقایسهها رو در چه زمانی انجام میده؟ پردازنده همه این مقایسهها رو در زمان تقریبی ۳.۳ میکروثانیه انجام میده!
| زمان مورد نیاز بر حسب ثانیه | تعداد عملیاتها |
| ۱ | ۹^۱۰ * ۳ |
| t | ۴^۱۰ |
t = 3.3 * 10^-6
خب پس توی این مثال، به هیچ مشکلی نمیخوریم. وقتی به مشکل میخوریم که محاسبات ما خیلی وقتگیر بشه. مثلا اگه محاسبات ۱ دقیقه وقت ببره، حالت خیلی مطلوبی برای ما نیست. برای این که مقایسههای کامپیوتر برای پیدا کردن شماره تلفن، ۱ دقیقه وقت ببره، باید چند تا شماره تلفن داشته باشیم؟ یک چیزی حدود ۱۸ میلیارد شماره تلفن! احتمالا در کل دنیا اینقدر شماره تلفن وجود نداره 🙂
پس دقیقا برای انجام چه کاری ما نیاز داریم که دادهها رو خیلی منظم و مرتب ذخیره کرده باشیم تا دسترسی بهشون ساده بشه؟ این سناریو رو در نظر بگیرین: یه فروشگاه اینترنتی که ۱۰۰ میلیون مشتری داره و هر کدوم از این مشتریها، ۱۸۰ فیلد دیتا دارند (منظور از فیلد دیتا، چیزهایی شبیه اسم و ایمیل و شماره موبایل، یا چیزهایی مربوط به رفتار کاربر در سایت فروشگاه اینترنتی مثل صفحات بازدیدشده و آیتمهای خریداریشده و … هست). میزان دیتای ما میشه ۱۸ میلیارد! خب حالا فرض کنید بخوایم بین این ۱۸ میلیارد فیلد داده، یه فیلد داده رو جستوجو کنیم! خب این کار حداقل یک دقیقه زمان میبره و این اصلا خوب نیست. توجه کنید که ما ممکنه بخوایم روزانه هزاران سرچ از این نوع انجام بدیم و اگه هر کدوم ۱ دقیقه زمان ببره، فاجعه پیش میاد! این جاست که یه نیازی پیش میاد. نیاز این که ما باید دادهها رو جوری ذخیره کنیم که خیلی منظم باشند و راحت بتونیم در زمان کمی بهشون دسترسی داشته باشیم؛ دقیقا مثل یک دفترچه تلفن منظمی که بر اساس حروف الفبا مرتب شده. حالا این که چه روشهایی برای منظم کردن این دادهها وجود داره، دقیقا موضوع مبحث ساختمان داده یا همون Data Structure هست. این موردم بگیم که در مباحثی مثل هوش مصنوعی، به خاطر این که معمولا با حجم دیتای خیلی زیادی سر و کار داریم، استفاده از ساختمان دادهها و الگوریتمهای بهینه ضروریه.
رابطه ساختمان داده (data structure) با الگوریتم (algorithm)
توی مثال جستوجو در شماره تلفنها، گفتیم که در بدترین حالت (یعنی حالتی که شماره مطلوب ما، آخرین شماره باشه)، ما باید به اندازه کل شمارهها مقایسه انجام بدیم. اما آیا راهی هست که با تعداد عملیات کمتری بتونیم به جواب برسیم؟ جواب این سوال، موضوع مبحث الگوریتم (algorithm) هست. در واقع در بحث الگوریتم، روشهای مختلف حل یک مسئله رو بررسی میکنیم که یک سریشون سریعتر و بهینهتر از بقیه هستند. اما طبق توضیحی که دادیم، گفتیم که برای افزایش سرعت سرچ، باید دادهها رو منظم ذخیره کنیم! بالاخره تکلیف چیه؟ ذخیره کردن مناسب دادهها باعث افزایش سرعت میشه یا استفاده از الگوریتم و روش درست برای پیدا کردن دادهها؟ هر دو! ما برای این که بهترین و پرسرعتترین عملکرد رو داشته باشیم، باید هم به طور منظمی دادهها رو ذخیره کنیم و هم از روشهای خوبی برای چرخ زدن در این دادههای منظمشده استفاده کنیم. ما توی این مقاله فعلا نمیخوایم در مورد الگوریتم صحبت کنیم و در ادامه فقط پیرامون موضوع ساختمان داده صحبت میکنیم. یه موضوع دیگه هم این جا پیش میاد! ممکنه یه نفر بگه به جای این که اینقدر به خودمون سختی بدیم و از ساختمان داده و الگوریتم مناسب استفاده کنیم، بریم و از یه پردازنده قویتر استفاده کنیم. حق حق حق 🙂 خیلی حرف حقیه. اگه شما پول پردازنده قویتر رو میخوای و داری که بدی، برو و بده!
تفاوت نوع داده (data type) و ساختمان داده (data structure)
بذارین با یه تقسیمبندی جذاب آشناتون کنیم:
ما میتوینم به طور کلی نوع داده (data type) رو به دو تا دسته تقسیم کنیم:
۱-نوع داده اولیه (primitive data type)
۲-نوع داده خودساخته (user defined data type)
نوع داده اولیه، نوع دادههایی هستند که به صورت اولیه در زبان برنامهنویسی تعریف شدهاند. مثلا در همه زبانهای برنامهنویسی، نوع دادههای int و float وجود دارند. توجه کنید که نوع داده اولیه در زبانهای مختلف ممکنه متفاوت باشه ولی فعلا نمیخوایم به این موضوع بپردازیم. در مقابل، نوع داده خودساخته، یک نوع دادهای هست که از اول وجود نداره و خود برنامهنویس به شکل دستی تعریف میکنه اون رو و معمولا هم از مجموعه چند نوع داده اولیه به وجود میاد. مثلا در زبان C میتونیم با استفاده از struct یک نوع داده تعریف کنیم که نمایانگر یک نقطه در صفحه باشه. به این شکل:
|
1 2 3 4 5 6 7 |
struct point{ int x; int y; } |
حالا یک حالت خاص نوع داده خودساخته، میشه نوع داده انتزاعی (Abstract Data Type یا ADT). خب حالا این انتزاعی یعنی چی؟ بذارین با یه مثال، این مفهوم انتزاع رو توضیح بدیم.
فرض کنید میخوایم یک خودرو بسازیم. همون طور که میدونید 🙂 خودرو از قطعات مختلفی ساخته شده! مثلا اگزوز (!)، پنجره، موتور، کولر، صندلی و …. در کشورهای پیشرفتهای مثل ایران که خودروسازی فناوری مهمی حساب میشه، هر بخش خودرو رو ممکنه یه کارخونه جداگانه بسازه و در نهایت قطعات با هم مونتاژ بشن و خودرو ساخته بشه. خب هر کارخونه در زمینه تخصصی خودش حرفهای هست و با سایر قطعات اصلا آشنایی نداره. بنابراین هر کدوم از قطعات باید کامل توسط کارخونه مبدا ساخته بشه و همراه اون قطعه یه راهنمای ساده قرار بگیره که «غیرمتخصصین» بتونن از اون قطعه استفاده کنند. اگر این راهنما کاملا ساده نوشته بشه و هر کسی با هر سطح تخصصی بتونه از اون استفاده کنه، کارخانه مبدا، «انتزاع» رو به خوبی رعایت کرده. در واقع انتزاع یعنی وارد پیچیدگیها و لایههای زیرین نشیم و فقط مطالب کاربردی رو به مخاطب منتقل کنیم.
برگردیم به کار خودمون! فرض کنید بخوایم یک نوع داده بسازیم و در اختیار بقیه قرار بدیم تا بقیه هم از نوع دادهای که ما ساختیم استفاده کنن. اگر انتزاع رو خوب رعایت کرده باشیم، بقیه اصلا نباید درگیر «جزئیات پیادهسازی» نوع داده ما بشن و فقط یک پوسته و روابط (interface) از اون در اختیارشون قرار بدیم و بتونن ازش استفاده کنن.
همونطور که احتمالا متوجه شدید، نوع داده انتزاعی (ADT)، یک چیز تعریفیه. یعنی این که چیزی نیست که وجود خارجی داشته باشیم؛ بلکه ما به بعضی از نوع داده یا حتی ساختمان دادهها ممکنه بگیم نوع داده انتزاعی. گیج نشید! بذارین اینطوری بگیم که یک نوع داده، میتونه انتزاعی باشه یا نباشه. انتزاعی بودن یا نبودن ربطی به نوع پیادهسازی اون نوع داده نداره. تامام!
خب حالا ساختمان داده چیه این وسط؟ یه جورایی میشه گفت ساختمان داده در واقع، راههای مختلف پیادهسازی واقعی ADTها هستند. مثلا یک نوع داده انتزاعی وجود داره به اسم صف (Queue)؛ این ADT رو میشه با ساختمان دادههای مختلفی مثل آرایه، لیست پیوندی (linked list) یا حتی گراف (Graph)، پیادهسازی کرد.
اگه گیج شدین خیلی مهم نیست! برین به قسمتهای بعدی و بعدا برگردین دوباره این قسمت رو بخونین. خیلیم چیز مهمی نیست واقعیتش و صرفا چند تا تعریفه 🙂
دادهها در کامپیوتر، دقیقا در کجا ذخیره میشوند؟
بستگی داره 🙂 منظورتون چه نوع دادهای هست؟ ما در کامپیوتر حافظههای مختلفی داریم که هر کدوم برای انجام کار خاصی ساخته شدند. اگه بخوایم به طور خیلی خلاصه بگیم، حافظههای در کامپیوتر میتونن این چیزا باشن:
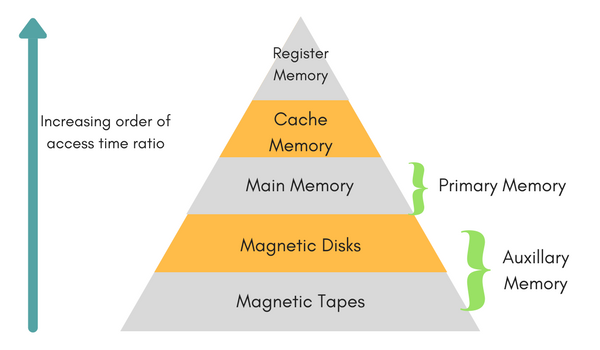
هر چه به سمت لایههای بالاتر حرکت کنیم، به پردازنده (CPU) نزدیک میشویم و مجبوریم به خاطر سرعت بالای پردازنده، از حافظههای سریعتری هم استفاده کنیم. بنابراین حافظههای بالای هرم سریعتر، گرانتر و نزدیکتر به CPU هستند. در برنامهنویسی و مبحث ساختمان داده، وقتی از حافظه صحبت میکنیم، معمولا منظورمون حافظه اصلی یعنی همون Main Memory هست. مثلا در کامپیوترهای امروز، حافظه اصلی حجمی در حدود ۸ یا ۱۶ گیگابایت داره. هارددیسک کامپیوتر که مثلا در حدود ۱ ترابایت هست، از نوع Magnetic Disc یا همون دیسک مغناطیسی هست. حافظه (منظور همون حافظه اصلی)، به بلاکهای کوچیکتری تقسیم میشه که هر بلاک یک آدرس خاصی داره.

تصویر پایینی یک تصویر شماتیک از حافظه اصلی با ۹ بلوک است که با سیستم دودویی، شمارهگذاری شده:
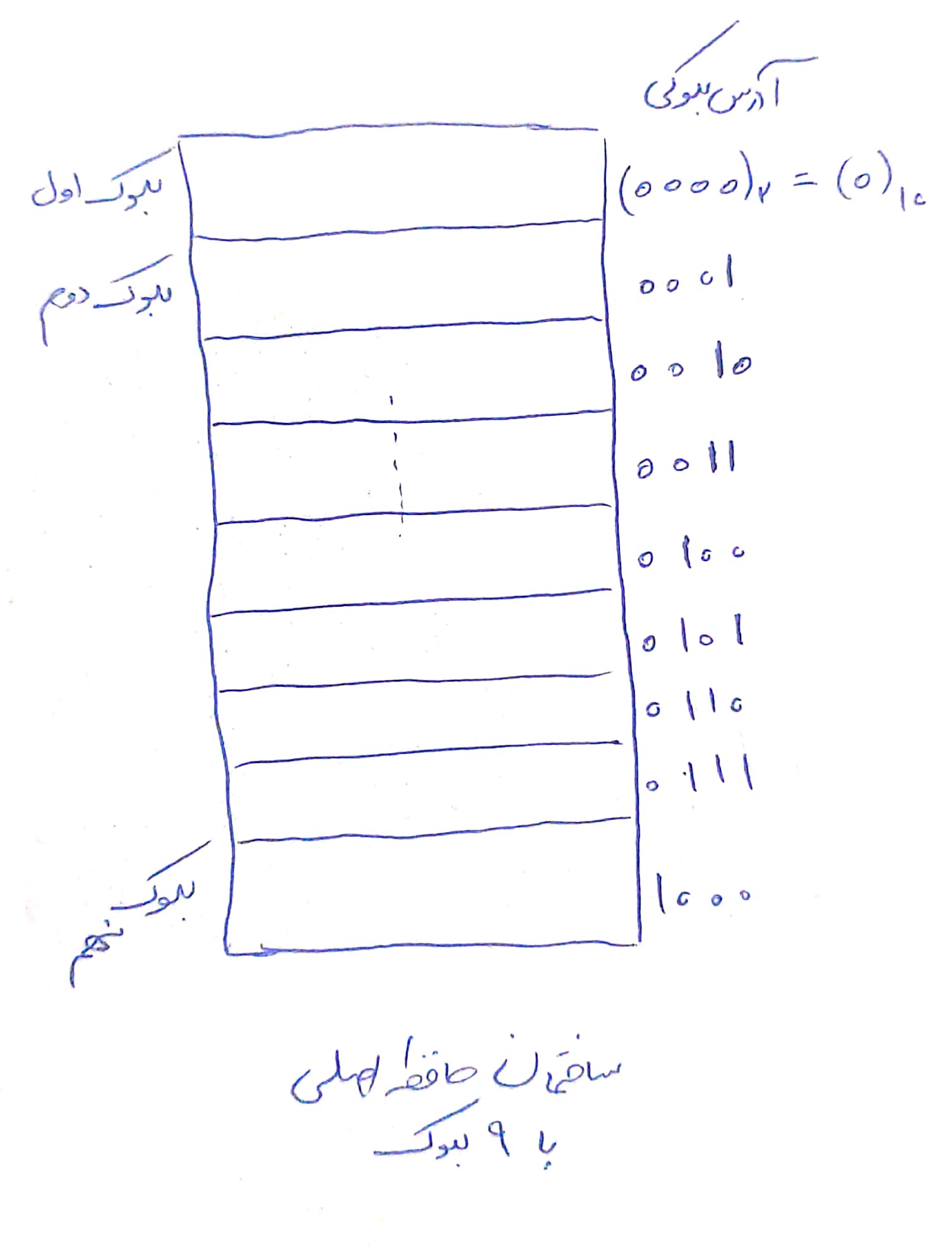
آخرین نکته هم این که هر کدوم از این بلوکها از واحدهای کوچکتری به اسم بیت تشکیل شدهاند. هر بیت فقط میتواند یک مقدار ۱ یا ۰ داشته باشه (همون صفر و یک معروف :)). وقتی این صفر و یکها کنار هم قرار بگیرند، واحدهای بزرگتری مثل int یا string رو میسازند که همون متغیرهای برنامههای ما هستند. پس میشه اینجوری تصور کرد که متغیرهای برنامه (که همه داخل حافظه اصلی ذخیره میشن)، هر کدوم یه آدرس خاص در حافظه دارند.
آرایه (Array)، سادهترین ساختمان داده
آرایه رو حتما میشناسین و قبلا ازش استفاده کردین. آرایه هیچ چیزی نیست جز چند تا متغیر همنوع که به شکل فیزیکی در حافظه اصلی کنار هم قرار گرفتهاند؛ به زبان دیگه، آرایه چند تا متغیره که آدرسهاشون پشت سر همه. ما این جا نمیخوایم وارد این موضوع بشیم که هر ساختمان داده رو چجوری میشه در زبانهای مختلف پیادهسازی کرد؛ خیلی هم مهم نیست راستش! با یه سرچ ساده میتونین فهمین که مثلا چجوری میشه یه آرایه توی جاوا تعریف کرد. این جا چیزی که برای ما مهمه مفهوم کلی هست و هر جایی هم که نیاز به کد نوشتن داشته باشیم، به جای کد، شبه کد (Sudo Code) مینویسم. مثلا شبه کد تعریف آرایه این شکلی هست:
|
1 |
ourLovelyArray = [1, 2, 3, 4] |
به همین سادگی تونستیم یه آرایه با ۴ تا عضو ایجاد کنیم که اسمش ourLovelyArray هست. هر عضو آرایه یه ایندکس داره؛ ایندکس یا شماره اعضای آرایه از صفر شروع میشن. این مثال رو ببینید:
|
1 2 |
ourLovelyArray[] = 1 ourLovelyArray[3] = 4 |
آرایه یه ساختمان داده خیلی خفنی هست که تقریبا همه چیز رو میشه باهاش پیادهسازی کرد. همون طور که دیدین، اضافه کردن عنصر با آرایه یا دسترسی به عنصر با ایندکس مشخص، با سرعت زیادی انجام میشه. اما آرایه یه محدودیت اساسی داره: همون طور که گفتیم، عناصر آرایه، در حافظه هم به شکل فیزیکی پشت سر هم قرار میگیرین؛ بنابراین لازمه که موقع تعریف آرایه، مشخص کنیم که آرایه ما چند تا عضو داره. این خیلی محدودیت بزرگی هست! خیلی اوقات ما حتی نمیدونیم دادهها چند تا هستند. مثلا در مثال فروشگاه اینترنتی، ما نمیدونیم مثلا یک سال دیگه چند تا مشتری داریم و باید آرایه رو چند عضوی در نظر بگیریم. این محدودیتها باعث شد برنامهنویسها یه ساختمان داده جدیدی بسازن به اسم لیست پیوندی یا linked list.
ساختمان داده لیست پیوندی (linked list)
خب میخوایم محدودیت آرایه رو حل کنیم؛ برای حل این محدودیت باید راهحلی ارائه کنیم که ما رو قادر کنه بدون این که دادهها رو به شکل فیزیکی در حافظه پشت سر هم قرار بدیم، بتونیم پیوستگی اونها رو تشخیص بدیم؛ یعنی بدونیم داده بعدی چیه.
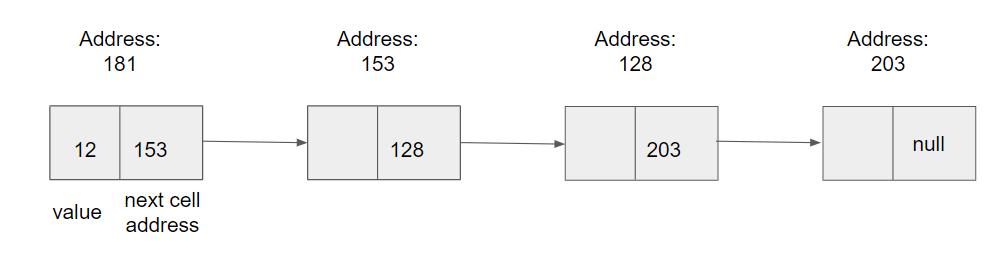
در واقع هر گره (node) در لیست پیوندی، دو قسمت داره: داده و آدرس خانه بعدی. به این ترتیب میشه در جاهای مختلف حافظه، گرههای لیست پیوندی رو ذخیره کرد و لازم نیست گرهها پشت سر هم باشند.
ساختمان داده، مبحث خیلی گستردهایه 🙂 این جا نمیشه واقعا همه مطالب رو منتقل کرد. حتما قسمتهای بعدی رو هم دنبال کنید که با جزئیات بیشتری ساختمان دادههای دیگه مثل صف (Queue)، پشته (Stack)، درخت (Tree) و گراف (Graph) رو بررسی میکنیم. موفق باشید 🙂





سلام قسمت های بعدی این مطلب آماده می شوند آیا؟
ممنون میشم ادامه پیدا کنه به همین صورت با جزئیات
سلام دوست عزیز
بله حتما ادامه پیدا میکنه
بسیار بسیار عالی توضیح دادین با تشکر
عالی بود
عااااااالی