


برای این که بفهمیم بیگ دیتا چیست، خوب است اول نگاهی به مفهوم دیتا یا داده بیندازیم. داده یا Data، مقادیر، کاراکترها یا سمبلهایی است که پردازشهای کامپیوتری بر روی آنها انجام میشود. دادههای میتوانند به شکل سیگنالهای الکتریکی ذخیره شوند یا انتقال یابند. همچنین دیتا را میتوانیم بر روی دیسکهای مغناطیسی، نوری یا مکانیکی ذخیره کنیم. بیگ دیتا یا کلان داده نیز همان دیتاست فقط در ابعاد و مقادیر خیلی خیلی بزرگ! کلان داده در حقیقت دیتایی بسیار حجیم است که در طول زمان به صورت نمایی بزرگ میشود. بیگ دیتا آنقدر بزرگ است که هیچ یک از ابزارهای سنتی مدیریت داده، قادر به نگهداری یا پردازش بهینه آن نیستند. در این مقاله از فنولوژی به این سوال میپردازیم که کلان داده چیست؟ و کاربردهای بیگ دیتا چیست؟
کاربردهای بیگ دیتا یا کلان داده
برخی از کاربردهای کلان داده عبارتند از:
- بورس نیویورک، روزانه در حدود یک ترابایت داده از معاملات مختلف تولید میکند.
- روزانه در فیسبوک، حدود ۵۰۰ ترابایت دادههای جدید از انواع مختلف بارگذاری میشود.
- یک موتور جت هواپیما، در ۳۰ دقیقه میتواند دیتایی با حجم ۱۰ ترابایت تولید کند.
انواع کلان داده چیست؟
بیگ دیتا یا کلان داده در سه فرم کلی زیر یافت میشود:
- دادههای ساختارمند (structured)
- دادههای بیساختار (unstructured)
- دادههای شبه ساختارمند (semi-structured)
داده ساختارمند یا structured data
هر دادهای که بتوان آن را با فرم مشخصی ذخیرهسازی، بازیابی و پردازش کرد، داده ساختارمند نام دارد. در طول زمان، پیشرفتهای مختلفی در زمینه کامپیوتر صورت گرفته و روشهای متنوعی برای کار با این نوع از دادهها، ارائه شدهاند. امروزه با چالشهای جدیدی رو به رو هستیم. دادهای ساختارمند امروزی، حجمی معادل چندین زتابایت (کیلوبایت، مگابایت، گیگابایت، ترابایت، پتابایت، اگزابایت، زتابایت!) دارند و این حجم عظیم، کار با آنها را سخت میکند. اگر دقیقتر به حجم این دادهها فکر کنید، متوجه میشوید که چرا نام کلان داده را یدک میکشند! پردازش و ذخیرهسازی این حجم از دادهها، با مشکلات بسیار متنوعی روبروست. دادههایی که در یک پایگاه داده رابطهای (relational database) ذخیره میشود، معمولا از نوع دادههای ساختارمند هستند. جدول زیر، مثالی از دادههای ساختارمند است:
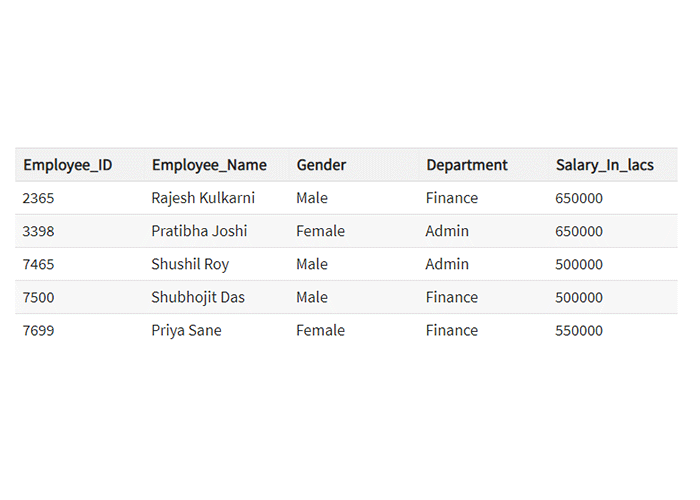
داده بی ساختار یا unstructured data
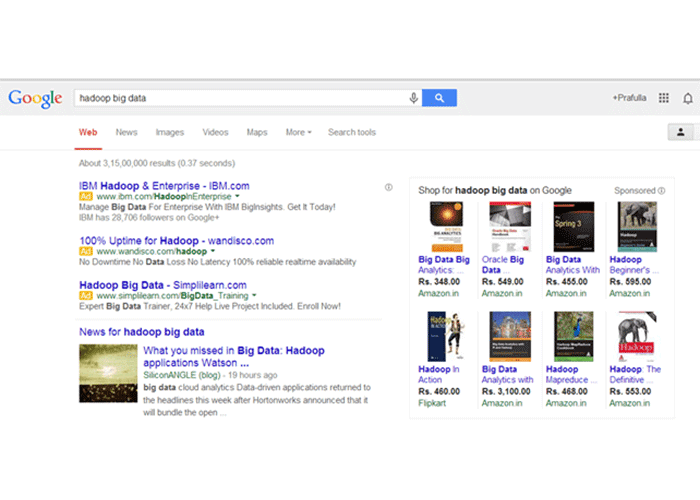
هر دادهای با فرم و ساختار نامعین و نامشخص، داده بیساختار نام دارد. دادههای بیساختار، علاوه بر پیچیدگیهای مربوط به حجم دادهها، پیچیدگیهای مختلفی در زمینه پردازش و استخراج اطلاعات از آن دارد. منابع دادهای ناهمگون که ترکیبی از انواع مختلف داده مانند دیتای تصویری، متنی، ویدیویی و … هستند، مثالی از دادههای بیساختار به حساب میآیند. سازمانها معمولا حجم عظیمی از دادههای مختلف دارند؛ اما بیساختاری این دادهها باعث شده که نتوانند استفاده درستی از آنهای کنند. صفحه سرچ گوگل، مثالی از داده بیساختار است:
داده شبه ساختارمند یا semi-structured data
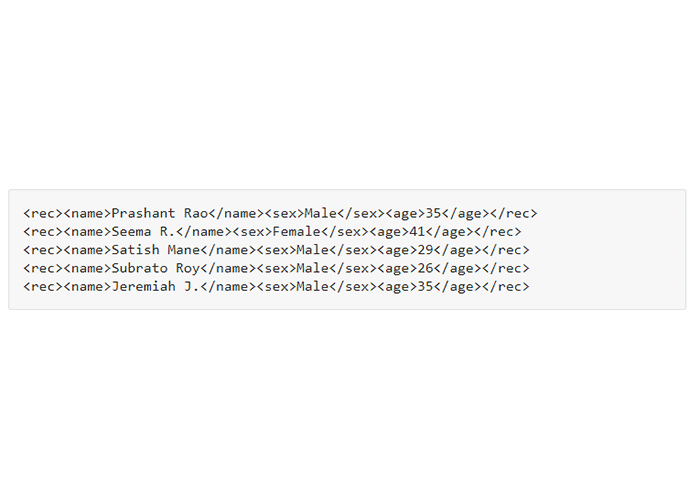
دادههای شبه ساختارمند در واقع ترکیبی از هر دو نوع دادهی ساختارمند و بیساختار هستند. در حقیقت، این دادهها فرم خاصی دارند ولی به شکل جدول (مانند دادههای ساختارمند) در نمیآیند. مثالی از داده شبه ساختارمند، یک فایل XML است که بخشی از آن را در تصویر زیر میبینید:
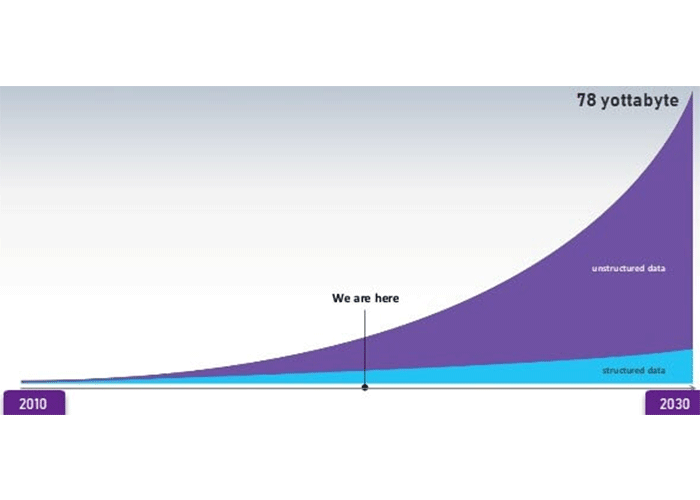
رشد کلان داده در طول زمان
دقت کنید که دادههای تولیدشده توسط وباپلیکیشنها، از نوع دیتا بیساختار هستند؛ زیرا این دادهها ترکیبی از فایلهای مختلف، دادههای مربوط به تراکنشها و … هستند. سیستمهای OLTP، تنها با دادههای ساختارمند (که در جداولی هستند) کار میکنند. در تصویر زیر، میزان دادههای ساختارمند و بیساختار تولیدشده از سال ۲۰۱۰ تا ۲۰۳۰ (پیشبینی) را مشاهده میکنید.
ویژگی های کلان داده چیست؟
حجم
واژه کلان داده بیانگر دادههایی است که حجم خیلی زیادی دارند. حجم داده آنقدر اهمیت دارد که یکی از ملاکهای ارزشگذاری دادههاست. این که یک مجموعه داده را کلان داده بنامیم یا نه، کاملا بستگی به حجم دادهها دارد. علاوه بر این، هنگام کار با دادهها و پردازش آن، نیاز است تا به حجم آن توجه ویژهای کنیم.
تنوع
به خاطر پدید آمدن منابع ناهمگون تولید دیتا، تنوع زیادی در کلان دادهها به وجود آمده است. در گذشته، صفحات گسترده (مثل مایکروسافت اکسل و گوگل شیت) و دیتابیسها، تقریبا تنها منبع دیتا به حساب میآمدند. امروزه، دادههای بسیار متنوعی به فرم ایمیل، عکس، ویدیو، PDF، صوت و … نیز در کاربردهای متنوع مورد توجه قرار گرفتهاند. تنوع زیاد دادههای بیساختار پیچیدگیهای فراوانی برای ذخیرهسازی و آنالیز این دادههای ایجاد میکنند.
سرعت
منظور از سرعت، سرعت تولید دادههای جدید است. در واقع ما باید بتوانیم پتانسیل تولید دادهها را اندازهگیری کنیم. حجم عظیمی از دادهها هر لحظه از طریق سنسورها، تلفنهای همراه هوشمند، شبکههای اجتماعی، شبکههای رایانهای و دادههای بیزینسی وارد دیتابیسها میشوند. این جریان داده به شکل دائمی و بسیار حجیم است.
فواید پردازش کلان داده چیست؟
توانایی پردازش کلان داده فواید فراوانی دارد؛ برخی از این فایدهها عبارتند از:
- کسبوکارها میتوانند از منابع هوشی قدرتمند در تصمیمگیریهایشان بهرهمند شوند
- پشتیبانی از مشتریان با خودکارسازی فرایندها بسیار راحتتر میشود
- میتوان با استفاده از کلان داده یا همان بیگ دیتا، ریسکهای احتمالی استارت یک کسبوکار را پیشبینی کرد
- بهینهسازی بیشتر عملیاتهای مختلف
جمعبندی
- بیگ دیتا، مجموعهای از دادههاست که حجم بسیار زیادی دارند. کلان داده علاوه بر حجم زیاد، سرعت رشد حجم نمایی نیز دارد.
- مثالهایی از بیگ دیتا عبارتند از: دادههای بورس، شبکههای اجتماعی، موتور جت و ….
- کلان داده میتواند ساختارمند، بی ساختار و شبه ساختارمند باشد.
- حجم، تنوع و سرعت از ویژگیهای کلان داده است.
- برخی از کاربردهای بیگ دیتا عبارتند از: بهبود عملیاتها، تصمیمگیری هوشمندانهتر، بهبود کیفیت سرویسدهی به مشتریان و ….
منبع: GURU99




