


رویداد Trace Way برای اولین بار توسط کوئرا، ۱۴ آذر ۹۸ در سالن آمفیتئاتر دانشکده انرژی دانشگاه صنعتی شریف با موضوع هوش مصنوعی و یادگیری ماشین برگزار شد. این رویداد تخصصی با هدف انتقال تجربهی توسعهدهندگان ارشد کسبوکارها و شبکهسازی آنها برگزار شد. در این رویداد شرکتهای توسعهدهندهی حرفهای و موفق تجربیات کاری خود در بهکارگیری هوش مصنوعی و یادگیری ماشین را با یکدیگر به اشتراک میگذارند. همچنین فرصت خوبی برای مرتبط کردن متخصصان این حوزه با شرکتهایی که به دنبال نیروهایی زبده و حرفهای هستند فراهم میشود. در ادامهی این گزارش از تیم خبری فنولوژی، کاربردهای هوش مصنوعی در ایران و کسبوکارهای موفق این حوزه بررسی شدهاند.

بخشهای مختلف رویداد Trace Way
رویداد Trace Way شامل معرفی فعالیتهای کوئرا، ارائههای اصلی در ابتدای همایش، ارائههای کوتاه در ادامه و شبکهسازی میان شرکتکنندگان بود. در ارائههای اصلی، افرادی از شرکتهای دیجیکالا، بلد، کافه بازار و تپسل تجربههای ارزشمند کاری خود را در استفاده از هوش مصنوعی برای ارتقاء محصولات و فروش خود ارائه دادند. همچنین در سخنرانیهای کوتاه پنچ دقیقهای شرکتهای سلام سینما، واکاویک و ویرگول به معرفی سیستم یادگیری ماشین مورد استفاده خود پرداختند.

هوش مصنوعی در ایران | محمد باقر تبریزی؛ مدیرعامل کوئرا
کوئرا ۴ سال پیش در دانشگاه شریف از یک سیستم کمک آموزشی برنامهنویسی شروع شد. کار این سیستم تصحیح تمرینات و پروژههای برنامهنویسی دانشجویان بود که به صورت منبع باز روی GitHub وجود داشت. این سیستم کمک آموزشی ایدهی اولیهی کوئرا بود که در ادامه با پیگیری فعالیتهایی از قبیل آموزش برنامه نویسی، برگزاری رقابت در این حوزه و استخدام نیروی ماهر توسعه پیدا کرد. اخیرا قسمت جدید کوئرا کالج با برگزاری آموزشهای تعاملی با زمان کم و تمرینات زیاد در کنار برگزاری رویدادهایی نظیر رویداد Trace Way از جدیدترین فعالیتهای کوئرا به حساب میآیند.

هوش مصنوعی در ایران | کاربرد یادگیری ماشین در تبلیغات دیجیتال شرکت تپسل
عباس حسینی، معاون فنی تپسل، ارائهی خود را در موضوعات مفهوم تبلیغات دیجیتال، انواع تبلیغات دیجیتال، سازوکار RTB، تخمین قیمت پیشنهادی و در نهایت مسیر طیشده توسط تپسل در این راهبرد، پیش برد.
در گذشته تبلیغات با روشهایی مانند بنرهای سطح شهر انجام میشد؛ اما این نوع تبلیغات کارایی پایینی نسبت به قیمت پرداختی داشتند. امروزه با پیشرفت رسانههای دیجیتال، به سمت تبلیغات دیجیتال پیش میرویم. در تبلیغات دیجیتال پای محاسباتی به میان میآید که به عنوان یک واسط میان تبلیغدهندگان (advertisers) و ناشرانِ (publishers) تبلیغات عمل میکند و با سازوکارهای مخصوص به خود سعی میکند در کمترین زمان ممکن و با بالاترین دقت، تبلیغات مناسب را به سمع و بصر کاربران برساند.
تبلیغات دیجیتال به دو دستهی مهم تقسیم بندی میشود: جستوجوی حمایتشده (Sponsored Search) و تبلیغات زمینه (Display Advertising).
جستوجوی حمایتشده، اولین مدل تبلیغاتی گوگل
در این نوع تبلیغات که هنوز هم طبق آمار عباس حسینی ۹۹ درصد عملکرد تبلیغاتی شرکت گوگل را تشکیل میدهد، وقتی شما عبارتی را در گوگل جستوجو میکنید مطابق با عبارت وارد شده تبلیغاتی از شرکتهای مختلف نمایش داده میشود. همچنین وقتی به دنبال برنامهای در Google Play یا کافه بازار هستید متناسب با موضوع، تبلیغاتی از این نوع به نمایش گذاشته میشوند. رقابت اصلی بین تبلیغدهندگان، روی کلیدواژههای حوزهی رقابتی آنهاست و قیمتهای پیشنهادی خود را برای این کلیدواژهها مطرح میکنند. طبیعی است هر شرکتی توقع دارد با پرداخت پول مناسبتر، هنگام جستوجوی کاربران نام و نشان خودش را بالاتر و پررنگتر مشاهده کند. وظیفهی موتورهای جستوجو و واسطهها این است که تبلیغات مناسب را با بیشترین قیمت ارائهشده، منتشر کنند. ویژگی مهم این نوع تبلیغات مشخص کردن مقصد دقیق و نیاز کاربر توسط خود کاربر و به کمک کلیدواژهای است که در موتور جستوجو سرچ میکند.
تبلیغات نمایشی (Display Advertising)
در مقایسه با تبلیغات حمایت شده، در بعضی سایتها در کنار محتوای متنی و پسزمینهی سایت شاهد تبلیغاتی هستیم که ظاهرا جزئی از فضای بومی سایت هستند؛ به این نوع تبلیغات، تبلیغات نمایشی گفته میشود. همچنین در برخی برنامههای گوشی اندروید و یا بازیهای معروف، جهت کسب امتیاز یا سکهی بیشتر به جای دریافت پول به شما پیشنهاد مشاهدهی تبلیغات داده میشود که مثال دیگری از تبلیغات نمایشی هستند.
در تبلیغات نمایشی، بر خلاف روش قبلی کاربر نیاز خود را به طور مستقیم و در موتور جستوجو ارائه نمیدهد و این وظیفه به دوش تامین کنندگان و الگوریتمهای تقسیمبندی (Segmentation) میافتد. در واقع اینجا به جای جنگ بر روی کلیدواژهها، تبلیغدهندگان روی قسمتبندیهای (segments) مختلف کاربران رقابت میکنند که بیشتر از روی سابقهی آنان دریافت میشود. برای مثال مردان ۲۰ سالهی علاقهمند به مسافرت یک نوع قسمتبندی از کاربران جامعه هدف است.
مکانیزم Real-Time Bidding) RTB)
در تبلیغات همواره، برخی شرکتها حاضرند با پرداخت بهایی به شرکت دیگر، تبلیغات خود را به آنان بسپارند. اما آیا شرکتهای تبلیغکننده تمام رسانهها را میشناسند و همهی رسانهها ظرفیت کار کردن با تعداد بیشمار این شرکتها را دارند؟
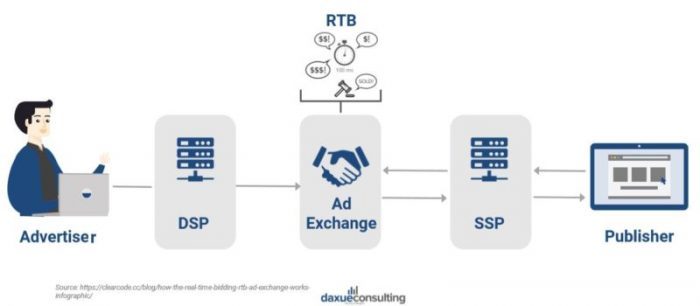
در این شرایط ضرورت شکلگیری واسطههایی برای هماهنگی و تسریع این فرایندها با استفاده از مکانیزم RTB به وجود آمدند. در این فرایند DSPها (Demand Side Platforms) مسئول جمعآوری، دسته بندی و ارائه دادن درخواستهای تبلیغدهندگان در یک سو، و در سوی دیگر SSPها (Supply Side Platforms) مسئول جواب دادن به درخواستهای DSPها و یافتن گزینههای خوب برای معرفی به رسانهها هستند. در این بین مبدل تبلیغ (AD Exchange)، وظیفهی به مزایده گذاشتن (Auctioning) و اختصاص دادن (Matching) نهایی درخواستها را بر عهده دارد.
نکتهی بسیار مهم اینجاست که زمان کل این فرایند نباید بیش از ۱۰۰میلی ثانیه به طول انجامد. برای مثال شرکت Turn DSP در لحظه ۱.۶ میلیون درخواست را مدیریت میکند و گوگل ۴۰ هزار سرچ در ثانیه را انجام میدهد.
اصلی ترین موضوع، ارزشگذاری مالی تبلیغات
شرکتهای تبلیغکننده، امروزه بیشتر به تبلیغات CPA یا Cost Per Action که منجر به عملیات مستقیم سودمند میشوند علاقهمندند. و ترجیح میدهند این روش را جایگزین تبلیغاتی کنند که صرفا با مشاهده (CPM) یا کلیک (CPC) پول میدهند. شرکتی که قصد تبلیغ دارد باید مطمئن شود از نظر اقتصادی ضرر نکند و مبلغی که صرف تبلیغات کرده موجب فروش بیشتر آن شود. برای تحقق این نیاز لازم است شرکتها ارزش مالی تبلیغات خود و میزان افزایش سود حاصل از این تبلیغ را دقیق بدانند که نقش یادگیری ماشین در اینجا شروع به درخشش میکند.
انواع روشهای پیشبینی ارزش تبلیغات
روشهای گوناگونی برای ارزشگذاری تبلیغات (Bid Estimation) وجود دارد که پایهی همهی آنها مطالعات آماری است که نشان میدهد چند درصد احتمال دارد کاربر از تبلیغات آنها استفاده کند. ابتدا تمام دادههای آماری باید به شکل یک بردار برای پردازش تبدیل شوند. روشهای آماری سادهتر، از سرعت بالاتر و کاربرد عمومیتری برخوردارند که البته باعث بروز خطاهایی از قبیل وابسته بودن به دادههای گذشته و عدم تطبیقپذیری بالا هستند. در مقابل، روشهایی که از یادگیری ماشین بهره میبرند بیشتر با سابقه و سلیقهی کاربر منطبق هستند و شانس به نتیجه رسیدن آنها تقویت میشود. چالش اصلی این روش کاهش زمان پاسخگویی است زیرا با افزایش دادهها و ابعاد بردار ذکرشده و پیچیده شدن محاسبات، باید با روشهای ارائه شده توسط دانشمندان داده و یادگیری ماشین زمان نتیجهگیری را در حد کاربردی کاهش دهیم. از مهمترین این روشها استفاده از عملگرهایی است که ابعاد ماتریس دادهها را بدون تاثیر در نتیجهی نهایی کاهش میدهند.

هوش مصنوعی در ایران: ماجرای تپسل
شرکت تپسل در همهی زمینههای ذکر شده وارد عمل شده و فعالیت میکند. در زمینهی جستوجوی حمایت شده، با کافه بازار همکاری صورت گرفته و در تبلیغات نمایشی در اکثر برنامههای تلفن همراه ایرانی و سایتهای مختلفی که روزانه با آنها سروکار دارید خدمات تپسل استفاده میشود. همچنیین در حوزه تبلیغات شبکههای اجتماعی با برند تگرو فعالیت میکند که Micro Influencer Advertising ارائه میدهد.
شرکت تپسل در ابتدای کار خود فقط ۵۰۰ عملیات در روز را مدیریت میکرد و فقط تبلیغات ویدیویی در اپلیکیشنها را شامل میشد که در ازای قرار دادن تبلیغ و کلیک گرفتن پول دریافت میکرد. در ادامه با توسعه فنی زیرساختها و توسعه راهبردی تپسل به تدریج به بیش از ۲۰۰ میلیون عملیات در روز رسید و الگوریتم تخمین قیمت آن کامل شد و ویژگی «تبلیغات به ازای کنشگری فعال» نیز به آن افزوده شد. علاوه بر آن زمان پاسخ الگوریتمهای تپسل به استانداردهای جهانی رسید و تپسل به کارگزاریهای خارج از کشور نیز متصل شد.
هوش مصنوعی در ایران | پردازش زبان طبیعی (NLP) در کافه بازار
علی چلمقانی، مدیر محصول هوش مصنوعی در کافه بازار، در مورد پردازش زبان طبیعی و استفادهی آن در کافه بازار در قسمت گفتوگوی برنامه دیوار صحبت کرد. او لیسانس کامپیوتر و فوق لیسانس خود را در رشته زبانشناسی رایانشی در دانشگاه شریف به اتمام رساند و در شرکت آرمان رایان شروع به فعالیت در زمینهی پردازش زبان کرد. سپس همکاری خود را با کافه بازار در موتور جستوجوی بازار و سپس در چت دیوار ادامه داد و در نهایت مدیر محصول تیم پردازش متن کافه بازار شد.
کافه بازار شامل سه محصول اصلی بازار، دیوار و بلد است که هرکدام مستقل فعالیت میکنند. و درکنار آنها به تازگی تیمی تحت عنوان هوش مصنوعی شکل گرفته که وظیفهاش ابتدا تامین نیازها و چالشهای ناتمام کافه بازار (تبدیل متن به گفتار، گفتار به متن و زیرساخت یادگیری ماشین دسته بندی متن و …) است. قسمت دادهی کافه بازار از تیم بزرگ و حرفهای شامل ۴۰ دانشمند داده و هوش مصنوعی و همچنین حجم زیادی از داده شامل یک میلیارد برهمکنش کاربر با محصولات کافه بازار و ۱۰۰ میلیون دادهی متنی تشکیل میشود. در ادامه به موارد مهم ارزش آفرینی این تیم میپردازیم که از مهمترین این موارد میتوان به چت دیوار اشاره کرد.

چت دیوار و یادگیری ماشین
اوایل سال ۹۶ چت دیوار کلید خورد و در اواخر سال با عیبیابی نهایی بهصورت رسمی عرضه شد و در سال ۹۷ حجم پیامهای چت دیوار در عرض یک سال ۳۰ برابر شد. توجه دیوار، حفظ حریم خصوصی کاربران و همچنین جلوگیری از مکالمات و گفتوگوهای مخرب و نامربوط در چت بود. در واقع هدف، اطلاع یافتن از میزان رضایتمندی و خدمترسانی به کاربران بود. بهترین راه برای اطلاع یافتن از این رضایتمندی استفاده از یادگیری ماشین و پردازش زبان طبیعی است.
روش یادگیری بدون ناظر (unsupervised learning)
چلمقانی میگوید: «در ابتدا با حجم زیادی دادهی حاصل از گفتوگوهای کاربران بودیم که نمیتوانستیم تشخیص دهیم موضوع بحث آنها چیست و برای حل این مشکل ناگزیر به استفاده از یادگیری بدون ناظر شدیم. با الگوریتمهای یادگیری ماشین موفق شدیم دادهها را به ۲۰۰ دستهبندی مجزا تقسیمبندی کنیم که فضای گنگ صحبتها را برایمان واضحتر کرد. مهمترین دستهبندیها شامل موارد فنی (مثلا مشخصات فنی ماشین مورد معامله)، آدرس گرفتن، معامله نهایی و مزاحمتهای ناخواسته در چتها بود. با این روش توانستیم ۳۰ درصد مزاحمتهای تشخیصدادهشده را برطرف کنیم و راه ارزیابی ما کاهش میزان بلاک کردن کاربران در مکالمات است.»
یادگیری ماشین در پیشنهاد هوشمند (Smart Suggestion)
در حال حاضر پیشنهاد هوشمند چت دیوار فعال است و در حین بحث به کاربر جملات آمادهای را پیشنهاد میدهد. چلمقانی میگوید: «با پیشرفت پردازش زبان طبیعی به این فکر افتادیم که از آن برای هوشمندتر کردن پیشنهادات خود استفاده کنیم که حین بحث وضعیت فعلی را تشخیص دهد و وابسته به آن به کاربر جملات اختصاصی خود را پیشنهاد دهد؛ بخش مهم این کار، پیشبینی موضوع بعدی است که کاربر قصد مطرح کردن آن را دارد.»
هدفگذاری آیندهی تیم هوش مصنوعی کافه بازار
چلمقانی دربارهی آیندهی کافه بازار میگوید: «تصمیم گرفتیم خدمات خود را از طریق زیرساخت ابری کافه بازار با سه هدف اصلی کاهش هزینه، ایجاد مزیت رقابتی و قابلیت مقیاس پذیری بالا به سایر کسبوکارهایی که نیاز به هوش مصنوعی دارند ارائه دهیم؛ چراکه جذب و پرورش نیروی متخصص داده کار پرهزینه و سنگینی است که ممکن است هر شرکتی نتواند در ابتدای کار از پس آن برآید.»
هوش مصنوعی در ایران | داستان مسیریاب بلد
پیام آراسته، دانشمند داده در مسیریاب بلد، از داستان شروع و توسعه و پیشرفت بلد و ارتباط آن با هوش مصنوعی و یادگیری ماشین صحبت میکند. همهی ما به ترافیک فکر کردهایم؛ ایدهی اصلی بلد بر اساس ترافیک شکل گرفت. اولین استفادهی بلد از ترافیک، نمایش ترافیک به صورت خطوط سبز، زرد و قرمز روی نقشه است. استفادهی دوم، تخمین زمانی رسیدن شما از مبدا به مقصد است و استفادهی سوم سوم، پیشنهاد بهترین مسیر طبق گرافهای مسیریابی و یالهای آن میباشد. در ادامه صحبتهای آراسته را درمورد بلد میخوانیم.

منبع ترافیک بلد خود کاربران بلد هستند
بعضی از کاربران تصور میکنند بلد برای جمعآوری دادهی ترافیک از تصاویر ماهوارهای یا دوربینهای سطح شهری پلیس راهبر استفاده میکند و یاحتی برخی تصور دارند افرادی استخدام شدهاند که درسطح شهر اطلاعات ترافیک را گزارش کنند. در عمل هریک از این موارد مشکلاتی دارند که مانع جمعآوری و اندازهگیری دقیق ترافیک میشوند. دادههای ماهوارهای در بهترین حالت یک هفته یکبار بهروزرسانی میشوند و برای تشخیص ترافیک از معابر اصلی و فرعی نیاز به پردازش تصویر بسیار سنگینی است. به دوربینهای پلیس راهبر نیز مجوز دسترسی نداریم و مجددا پردازش تصویر زیادی را طلب میکند.
اما بلد از دادههای کاربران خود استفاده میکند؛ کاربرانی که با در دست داشتن برنامه بلد در جای جای شهر قدم میگذارند. اما چگونه اطلاعات از کاربر گرفته میشود؟ راه اول گزارش دادن کاربران از وضعیت ترافیکی موقعیت خود در اپلیکیشن است که منجر به بهروزرسانی دادههای بلد میشود. مشکل این روش، داوطلبانه بودن آن است؛ چراکه همهی کاربران این کار را انجام نمیدهند و باعث ناقص بودن دادهها میشود.
روشی که بلد استفاده میکند GPS کاربران است که از لحظهی تصمیم حرکت شما از مبدا به مقصد فعال میشود. حریم خصوصی کاربران از ابتدا برای بلد اهمیت داشتهاست؛ لذا محل ذخیرهسازی دادهی شخصی کاربران شامل نام، تلفن، ایمیل و … در یک دیتابیس کاملا مجزا از دیتابیس ترافیک آنهاست. در اصل با نصب بلد توسط هر کاربر، یک توکن تصادفی برای او درنظر گرفته میشود که توسط آن توکن سیگنالهای GPS دریافت میشود و بلد نمیتواند تشخیص دهد این داده متعلق به کدام کاربر است.
مشکل نویز در دادهها
یکی از چالشهای پیش رو در تحلیل داده، نویز دادهها بود. سگنالهای GPS موقعیت مکانی کاربر را در مسیری نزدیک ولی متفاوت از مسیر اصلی جاده نشان میدهند که خود را بصورت نویز نمایش میدهد. برای حل این مشکل از تطابق نقشه (Map Matching) استفاده میکنیم که مسیر سیگنالهای یافتهشده را به نزدیکترین و بهترین جادهی در حال حرکت کاربر منطبق میکند. تطابق نقشه به شکلهای آنلاین و آفلاین استفاده میشود و فرآیند نسبتا پیشرفتهای از نظر محاسباتی است.
تشخیص سرعت
برای تشخیص سرعت حرکت ماشینها در یک مسیر و پیشنهاد سرعت مناسب به کاربر از دادههای کاربران مختلف استفاده میکنیم. با رصد کردن مکان کاربر در یک بازهی زمانی به راحتی سرعت کاربران در یک جاده محاسبه میشود اما چالش اصلی انتخاب مناسبترین سرعت پیشنهادی است. اگر بخواهیم از میانگین سرعتها استفاده کنیم، با داشتن دادههای پرت مانند سرعتهای بسیار بالا یا پایین میانگین عوض میشود و نشانگر مناسبی نیست. هم چنین اگر از دادهی وسط استفاده کنیم، کاربران ممکن است بتوانند با سرعت بیشتری نیز حرکت کنند و اگر از بزرگترین داده استفاده کنیم با خطاهایی از جمله خطای محاسبه GPS و بیشتر بودن سرعت ماشینهای اورژانسی مواجه میشویم. برای حل این چالش سیستم ترافیک خود را به روشی جدیدی توسعه دادیم.
با دریافت سرعت جدید از کاربر ابتدا سعی در فیلتر کردن آن سرعت با دو شرط اصلی داریم. یکی قرار نداشتن سرعت در بیشترین بازهی فراوانی و دوم عدم اطمینان از سرعت دریافتی است. در شرط اول سرعتهای قبلی خود را روی نمودار توزیع فراوانی زنگولهای شکلی تنظیم میکنیم که دارای میانگین و انحراف معیار است. بیشترین فراوانی دادهها در قسمت میانی این نمودار است که ۶۸ درصد دادهها را شامل میشود. اگر سرعت جدید در این ۶۸ درصد نباشد فیلتر میشود. در شرط دوم که اطمینان (Confidence) است، دو پارامتر مهم تحت عنوان Recency (میزان ارسال سرعت به تازگی) و Frequency (تعداد سرعتهای فرستاده شده در واحد زمان) سنجیده میشوند. اگر سرعتی فیلتر نشد و مجبور به بهروزرسانی وضعیت ترافیکی شدیم طبق یک میانگین حرکتی آماری و با توجه به دادههای قبلی و البته ضرایب تعدیل مختلف و پارامترهای ذکر شده، دادهی جدید را اعمال میکنیم.
چالشهای بلد در تخمین سرعت و راهحل آنها
پراکندگی (Sparsity) دادهها یکی از چالشهایی بود که در ابتدا برای حل آن، زمان دریافت سیگنالها را از ۱۰ دقیقه به ۲۰ دقیقه افزایش دادیم. در ادامه با افزایش تعداد کاربران، خودبهخود مشکل پراکندگی تا حد زیادی برطرف شد. چالش دیگر نحوهی اثر دادن گزارش مردم از وضعیت ترافیک سطح شهر در بلد بود. گزارش کاربران برای بازههای فراوانی کمتر نیز در نمودار زنگولهای شکل اثرگذار میشود و به این شکل با سختگیری کمتر، از این دادهها استفاده میشود. چالش دیگر تونلها و یا دیگر مکانهایی بود که سیگنالی از آنها دریافت نمیشد. برای حل این مشکل، با داشتن مسافت تونل و سرعت ابتدا و انتهای تونل یک سرعت میانگین تقریبی به دست میآید که مبنا قرار میگیرد.
پیشبینی ترافیک، گام بعدی بلد
ترافیک ذاتا یک موجود زمانی مکانی است و شرایط مختلف زمانی و مکانی بر آیندهی ترافیک تاثیر زیادی میگذارد. برای پیشبینی ترافیک تصمیم گرفتیم از گراف شبکههای عصبی استفاده کنیم. در زمانهای مختلف یک بردار متناظر با یک گراف، که نمایندهی ترافیک در آن لحظه است، وجود دارد. به این شکل مکان را با گراف و زمان را با بردار متناظر آن مدلسازی کردیم. با پیشبینی گراف n+1ام توسط بردار زمان متناظر میتوان به این مهم دست پیدا کرد که امیدواریم بتوانیم این تکنولوژی را در بلد پیادهسازی کنیم.
در آخر با اینکه ما در ابتدا قصد استفاده از شبکههای عصبی در پیشبینی ترافیک داشتیم اما واقعیت امر اینجاست که بلد با مطالعات سادهی آماری توانسته به بسیاری از نیازها و اهداف خود و کاربرانش برسد؛ لذا همیشه برای پیشبرد اهداف چنین شرکتهایی، نیاز به افتادن در مارپیچ تودرتوی یادگیری عمیق و الگوریتمهای پیچیدهی هوش مصنوعی نیست!

هوش مصنوعی در ایران | دیجی کالا
حامد دهقانی، مهندس داده در دیجیکالا، از تاثیر هوش مصنوعی بر سیستم پیشنهاددهنده (Recommendation System) دیجیکالا میگوید. پلتفرم دیجیکالا شامل یک قسمت Supernova است که به صورت کلی اپلیکیشنها و سایتهای مختلف مثل دیجیکالا، دیجیاستایل و … روی آن سوار هستند و حجم ترافیک بسیار زیادی از آنها عبور میکند. برای مدیریت این حجم زیاد داده، نیاز به پلتفرمی داشتیم که بتوانیم تمام فرآیندهای کاربر را برای کاربردهایی که نیاز به دادهی لحظهای (Real-time) دارند استفاده کنیم. دادههای دیجیکالا به دو بخش تقسیم میشود؛ دادههای کسبوکار، که در پسزمینهی پلتفرم Supernova است، و دادههای رفتاری (Behavioral) کاربران. برای ارائهی سیستم پیشنهاد هوشمند باید این دو نوع داده را با هم تلفیق میکردیم تا به بینش مفیدی از نیازهای کاربران برسیم.

سیستم پیشنهاددهنده دیجیکالا شامل ویژگیهای شخصیسازیشده و غیرشخصیسازیشده است. تا الان دیجیکالا بیشتر به صورت پیشنهاد لحظهای و یا دستهبندیهای مرتبط پیشنهاد میکرد و از شرکت واسطهای برای این منظور بهره میبرد. استفاده از این شرکت واسطه معایب زیادی از جمله هزینهی بسیار زیاد و مشکلات اجرایی آن در پلتفرمهای مختف و عدم نظارت کامل بر رضایتمندی کاربر و عملکرد نهایی سیستم به همراه داشت. البته سیستمهای پیشنهاددهندهی منبع باز (Open Source) زیادی نیز وجود دارند که آنها نیز محدودیتهایی از جمله عدم تطابق کامل با دیجیکالا و نیاز به بهبود الگوریتمها و شخصیسازی آنها دارند. به همین دلیل، دیجیکالا برای حذف شرکت واسطه و توسعهی سیستم پیشنهاددهنده بومی و ارائهی آن به صورت خدمات به سایر شرکتها (as a service) دست به کار شد. این پلتفرم شامل دو بخش مجزا است؛ یکی جریان ورودی داده از سمت کاربران به Storage که بهصورت آفلاین نیز کار میکند (بخش شخصیسازی نشده)، و دیگری قسمت Nearline است که باید به صورت لحظهای (Real-time) کار کند (بخش شخصیسازی شده).
این سیستم پیشنهاددهنده، شامل دستهبندیهای مختلفی مانند دستهی پربازدید هر کاربر، دستهی مورد علاقهی هر کاربر، دستهی برندهای پر بازدید کاربران و یا محصولات مرتبط جستوجوشده است. همانطور که اشاره شد بخشی از این دستهبندیها به صورت آفلاین و شخصیسازینشده و بخشی Real-time و شخصیسازیشده هستند.
بعضی مشکلات و چالشهای سیستم پیشنهاددهنده
یکی از چالشهای این سیستم وقتی پدید میآید که کاربران روی یک سری دستهبندیها به تعداد بسیار بالایی کلیک میکنند و این نرخ بالای کلیک اگر به عنوان یک پارامتر مهم در ارزیابی آفلاین لحاظ شده باشد میتواند باعث بروز خطا شود. یکی از چالشهای دیگر، تصمیمگیری در مورد حذف کالایی از لیست پیشنهادات یک کاربر پس از اضافه کردن آن به سبد خرید است. اگر کالایی مانند گوشی همراه خریداری شده باشد بهتر است دفعات بعدی از پیشنهادات کاربر حذف شده و در عوض لوازم جانبی آن محصول پیشنهاد شود اما اگر کالایی مانند شیر خشک و کالاهای مصرفی باشند، نباید از لیست پیشنهادات کاربر حذف شوند. تشخیص دادن و متمایز کردن این موارد استثنا از سیستم پیشنهاد عمومی برای هر دستهبندی مجزا، یکی از نکات کلیدی و مراحل پیشرفتهی این سیستم به حساب میآیند.

شبکه سازی در رویداد Trace Way
یکی از اهداف مهم سیستم پیشنهاددهندهی دیجیکالا، ارائهی پیشنهاداتی به شما با توجه به الگوی برداشتهشده از کاربری مشابه شما است. برای حل این موضوع، باید با چالشهایی از جمله میزان اهمیت دادههای تاریخی و پیشینهی کاربران توجه کنیم. همچنین برای پیشنهاددادن محصول به کاربرانی که تازه وارد سایت میشوند و آنهایی که پس از مدتی طولانی وارد سایت میشوند نیز باید تمهیداتی اندیشه شود. مثلا آیا بهتر است برای کاربری که پس از مدتی طولانی وارد سایت شدهاست از دادههای قدیمی او استفاده شود و یا با حذف سوابق، به عنوان یک کاربر جدید به او پیشنهاد داده شود.
در آخر دهقانی گفت: «در نهایت برای امتحان و ارزیابی سیستم جدید و بومی خود ابتدا در کنار سیستم خارجی واسطه، آن را به صورت A/B testing راه اندازی کردیم. با راه اندازی سیستم جدید شاهد عملکرد چشمگیری بودیم که حتی در مواردی از سیستم خارجی بهتر و بهینهتر اجرا شد. این عملکرد بهبود یافته از شخصیسازی بالا و دید بهتری که مهندسان ما از دادههای کاربران خود داشتند نشات گرفته و ما پیشبینی این رشد عملکردی را داشتیم. خوشبختانه در مواردی نیز که با ترافیک سنگینی از داده مواجه شدیم مانند یلدای دیجیکالا، سیستم بومی و جدید ما موفقیتآمیز از پس مسئولیت خود بر آمد.»
هوش مصنوعی در سینما
هادی راسخ از شرکت سلام سینما، دربارهی اهداف شکلگیری سلام سینما و توسعهی آن با هوش مصنوعی سخن گفت. سلام سینما با هدف اطلاع رسانی برای عاشقان دنیای فیلم و سینما شکل گرفت و میخواست مکانی برای یافتن، ارزیابی، و دستهبندی فیلمهای سینما باشد تا افراد بتوانند به راحتی فیلمهای مورد علاقهی خود را پیدا کنند. اما مشکل اینجاست که تعداد فیلمهای ساخته شده در دنیا بسیار بالاست و سالیانه تقریبا ۲۰۰۰ فیلم ساخته میشود. اگر کسی قصد تماشای آنها را داشته باشد باید روزی ۳۰ فیلم ببیند! اینجا بحث سیستمهای پیشنهاددهنده به میان میآید که به افراد بر حسب سلیقهی آنها فیلم پیشنهاد میکند. در ایران سالانه از فیلمهای زیادی که اکران میشوند تعداد کمی فروشهای بالای ۱۰ میلیارد تومان دارند و بسیاری از فیلمهای بسیار موفق و خوب از چشم افراد دور میمانند. این نشان از کمبود آگاهی مردم از بسیاری از فیلمهای خوب و باکیفیت ایرانی است و نشان میدهد بیشتر بازاریابی سینمای ایران، هنوز به روشهای سنتی مثل بیلبوردها و تبلیغاتی به این شکل انجام میشود.

هادی راسخ درمورد استفاده از هوش مصنوعی در سلام سینما میگوید: «ما برای شروع کار از سیستم پیشنهاددهنده منبع باز PredictionIO استفاده میکردیم که در ابتدا نیازهای سلام سینما را تا حد زیادی برطرف میکرد. در ادامه با توجه به بروز محدودیتهایی، تصمیم به توسعهی سیستم پیشنهاددهنده بومی خود گرفتیم. در این سیستم از الگوریتم ALS که برگرفته از نسخههای PredictionIO است استفاده میشود. این سیستم نیز دارای محدودیتهایی از جمله تغییر سلیقهی کاربران در طول زمان است. ما در حال توسعهی الگوریتمهای جدید برای بهبود این موارد هستیم.»
هوش مصنوعی در واکاویک
آرمان فاطمی از راهحل های هوش مصنوعی که واکاویک ارائه کردهاست گفت. واکاویک تلاش میکند راهکارهای هوش مصنوعی را به صورت Software As a Service به کسبوکارها ارائه کند تا نیازی نباشد همهی شرکتها خودشان درگیر برطرفسازی نیازهای هوش مصنوعی خود شوند.

در چند سال اخیر، شرکتها با نرخ بسیار زیادی برای تامین نیازهای خود به سمت راهکارهای هوش مصنوعی پیش رفتهاند. تقریبا شرکتی نیست که ادعا کند هیچ گونه نیازی به هوش مصنوعی برای بهبود عملکرد خود ندارد. هوش مصنوعی در زمینههای گستردهای از بازاریابی گرفته تا قیمتگذاری محصولات و حتی در منابع انسانی کاربرد دارد. اولین باری که کاربرد هوش مصنوعی در منابع انسانی توسط شرکتی به ما پیشنهاد شد، برای خودمان هم غیر منتظره بود. درخواست آن شرکت تحلیل رفتار، خلقیات و وضعیت روانی کارمندانش از روی توییتهای سازمانی آنها در محیط کار بود.
شرکت اوبر برای کارمندانش سیستمی به اسم «مایکل آنجلو» ارائه داده است که اجازه میدهد هر عضو بتواند هرجا نیاز داشت از راهکارهای هوش مصنوعی استفاده کند. این پلتفرم فقظ مخصوص کارمندان اوبر است؛ لذا برای ما قابل دسترسی نیست. اما احتمالا بسیار شخصیسازیشده عمل میکند و قابلیت انتخاب بین الگوریتمها و دیتابیسهای مختلف را دارد. برای تحقق چنین پلتفرمی نیاز به قابلیت اختصاصپذیری (Customization) بالایی است.
سوال مهم اینجاست که آیا استفاده از دادههای بزرگ لزوما برای دستیابی به چنین پلتفرمی مفید است؟ به نظر آرمان فاطمی لزوما اینطور نیست زیرا حجم زیاد داده چالشهای زیادی مانند چالش ذخیرهسازی دارد. همچنین تحلیل و دستهبندی و نگهداری از این دادههای بزرگ میتواند کار پرهزینه و کمبازدهی باشد.
در کسبوکارها استفاده از دادههای کوچک در بعضی موارد میتواند این مشکل را برطرف کند. پیشنهاد واکاویک این است که لزوما برای هر کاربردی که نیاز به هوش مصنوعی دارد نیاز به بومیسازی و درگیر شدن با چالشهای دادههای زیاد و الگوریتمهای پیچیدهی هوش مصنوعی نیست و میتوان از شرکتهایی که این خدمات را ارائه میدهند نیز کمک گرفت.
هوش مصنوعی در ایران | ویرگول
علی آجودانیان از مجموعهی ویرگول درمورد استفادهی هوش مصنوعی در ویرگول میگوید. مجموعهی ویرگول سعی در خدمترسانی و ارائهی بهترین پیشنهادات در حوزههای محتوایی تکنولوژی برای عاشقان این زمینهها دارد. ویرگول کار خود را از Recommendation System شروع کرد که با توجه به موضوع مطالب خواندهشده و یا نویسندهی آنها به کاربران پیشنهاداتی از جنس سلیقهی کاربر داده میشود. موارد تاثیرگذار، درصد متن خواندهشده توسط کاربر، نظر دادن یا ندادن، لایک کردن، نشان کردن و … بودند. به دلیل نواقص این طرح گامهای بعدی، نشان دادن شبیهترین متن به متن خوانده شده توسط کاربر در انتهای مقاله بود که این نیز خیلی جواب نداد. گویی آخر یک مسابقه فوتبال به کاربر پیشنهاد همان مسابقه با گوینده متفاوت داده میشد. برای حل این مشکلات مطالب را دستهبندی کردیم و از طریق این دستهبندیها کاربر میتوانست به زمینههای مورد علاقهاش دسترسی پیدا کند.

این روند به خوبی پیش میرفت تا اینکه دیدیم نکات ریزی که در ویرگول به چشم نمیآمد چقدر میتواند مفید باشد. برای مثال فالو کردن فرآیندی بود که تا پنج تا شش ماه پیش تفاوتی برای ویرگول نداشت اما به تازگی یافتیم که اگر مقالهای در آخر کار فالو شود ارزشمندتر از مقالهایست که در ابتدا و قبل از خواندن متن توسط کاربر فالو میشود. نهایتا اگر کاربر پس از مراجعه به پروفایل نویسنده آن را فالو کرده باشد از اهمیت دو چندان آن نویسنده خبر میدهد. به تازگی و به طور محدود در حال تست کردن سیستم یادگیری ماشین جدید خود هستیم که با توجه به نحوهی فالو کردن کاربران به آنها پیشنهاد میدهد. تا اینجا از عملکرد سیستم راضی هستیم و انشاالله به زودی این سیستم را به طور گسترده برای تمامی کاربران اجرایی میکنیم.

شبکه سازی در رویداد Trace Way




