

شبکه عصبی پیچشی یا شبکه عصبی کانولوشن! ترکیبی از کلمات عجیب و غریب به نظر میآیند! ترکیبی از علوم مختلف مانند ریاضیات، زیستشناسی و کامپیوتر. این شبکهها، از مهمترین نوآوریها در حوزهی بینایی کامپیوتر به حساب میآیند. لغت شبکه عصبی در سال ۲۰۱۲، معروفیت فراوانی کسب کرد؛ در این سال الکس چریشفسکی (Alex Krichevsky)، با استفاده از شبکه عصبی توانست برنده جایزه ImageNet (المپیک سالیانه بینایی کامپیوتر) شود. چریشفسکی توانست خطای دستهبندی (classification) را از ۲۶ درصد به ۱۵ درصد کاهش دهد. این کاهش در آن زمان بسیار چشمگیر بود و موفقیت بزرگی به حساب آمد. از آن زمان، شرکتهای متعددی از یادگیری عمیق به عنوان هسته اصلی محصولات خود استفاده کردهاند. فیسبوک از شبکه عصبی استفاده میکند تا تصاویر را به صورت خودکار تگگذاری نماید؛ گوگل نیز از این فناوری برای جستوجوی تصویری خود بهره میبرد. شرکتهایی مانند آمازون، اینستاگرام و پینترست نیز برای ارائهی پیشنهادهایی مناسب به کاربران خود، از شبکه عصبی کانولوشن (شبکه عصبی CNN) استفاده میکنند؛ با این حال بیشترین استفادهی شبکه عصبی در پردازش تصویر است. در این مقاله از فنولوژی، به این سوال میپردزیم که شبکه عصبی کانولوشن چیست و چگونه از آن در دستهبندی تصاویر استفاده میشود.

الزام استفاده از شبکه عصبی کانولوشن چیست؟
دستهبندی تصاویر (image classification) در حقیقت فرایندی است که در آن تعدادی تصویر از ورودی میگیریم و در خروجی، کلاس آنها (سگ، ماشین، خانه و …) یا درصد احتمال تعلق به هر کلاس را مشخص میکنیم. برای ما انسانها، این کار تقریبا جزء بدیهیات است؛ در حقیقت از زمانی که متولد میشویم تا وقتی که به یک انسان بالغ تبدیل شویم، به مرور و به شکل طبیعی این کار را به خوبی فرا میگیریم. ما میتوانیم بدون هیچ اشتباهی تمام اشیای پیرامون خود را تشخیص دهیم. به طور دقیقتر، ما هر گاه به محیط پیرامون خود نگاه میکنیم، تمام اشیا را تشخیص و به هر یک از آنها یک نام (label) اختصاص میدهیم. انجام چنین عملی، یعنی تشخیص و نامگذاری اشیای موجود در یک محیط، برای کامپیوتر، آنقدر ها هم کار راحتی نیست!

ورودی و خروجی در یک شبکه عصبی کانولوشن یا CNN
وقتی یک کامپیوتر تصویری را به عنوان ورودی دریافت میکند، آن را به صورت آرایهای از اعداد میبیند. تعداد آرایهها به سایز تصویر (بر اساس پیکسل) بستگی دارد. برای مثال اگر یک تصویر رنگی با فرمت JPG و اندازه ۴۸۰*۴۸۰ پیکسل را به کامپیوتر دهیم، آرایه جانشین آن دارای ۴۸۰*۴۸۰*۳ خانه خواهد بود (عدد ۳ به RGB برمیگردد). هر کدام از خانههای نیز عددی بین ۰ تا ۲۵۵ را میگیرند. این عدد شدت پیکسلی را نشان میدهد. این اعداد هر چند برای ما بیمعنی به نظر میرسند، اما در دستهبندی تصاویر با استفاده از شبکه عصبی کانولوشن، تنها ابزار در دست ما، چنین اعدادی هستند. ایده اصلی آن است که به رایانه آرایهای از اعداد شبیه آن چه توضیح دادیم، میدهیم و کامپیوتر نیز در خروجی چنین چیزی را مشخص میکند: این تصویر با احتمال ۸۰ درصد گربه، با احتمال ۱۵ درصد سگ و با احتمال ۵ درصد، پرنده است.
شیوه عملکرد شبکه عصبی کانولوشن چیست؟
تا این جای کار به مسئلهی مد نظر و ورودی و خروجی آشنا شدیم. بیایید به این فکر کنیم که به چه متدی مسئله را حل کنیم. چیزی که ما از کامپیوتر میخواهیم آن است که به تصاویر نگاه کند و ویژگیهای منحصر به فرد یک شیء خاص مثل کتاب را بداند و تشخیص دهد در تصویر، کتاب موجود است یا نه. ما انسانها نیز هنگام تشخیص اشیا، این فرایند را به صورت ناخودآگاه انجام میدهیم. ما مثلا وقتی یک سگ را میبینیم، برای آن که تشخیصش دهیم، ابتدا به اندام جزئیتر آن مانند گوشها، پنجهها، پاها و … توجه میکنیم و ضمن تطبیق با الگوهای موجود در ذهنمان، میفهمیم که در حال دیدن یک سگ هستیم. یک کامپیوتر نیز برای درک و تشخیص تصویرهای پیچیدهای مثل تصویر یک سگ، ابتدا ویژگیهای (feature) سادهتر آن تصویر مانند لبهها و خمها را تشخیص میدهد. در یک شبکه عصبی، لایههای متعددی وجود دارند؛ در هر یک از این لایهها، ویژگیهای خاصی تشخیص داده میشوند و در نهایت، در لایهی آخر، تصویر به طور کامل شناسایی میشود. روندی که توضیح دادیم، فرایند کلی نحوه کار یک شبکه عصبی کانولوشن بود؛ حال به جزئیات بیشتری میپردازیم.
ارتباط شبکه عصبی پیچشی با زیست شناسی!
در این قسمت میخواهیم کمی به مفاهیم پایهایتر بپردازیم. احتمالا بار اولی که عبارت شبکه عصبی کانولوشن را شنیدهاید، یاد زیست شناسی و نوروساینس افتادهاید. البته خیلی هم به بیراهه نرفتهاید! ساختار شبکه عصبی پیچشی (CNN) در حقیقت از قشر بینایی مغز الهام گرفته شده است. در سال ۱۹۶۲، دو دانشمند با نامهای هابل و ویزل، آزمایش جالبی انجام دادند. آنها نشان دادند که با دیدن لبهها با اشکال مختلف، سلولهای خاصی در قشر بینایی مغز تحریک میشوند. برای مثال با دیدن خطوط افقی، سلولهای خاصی تحریک میشوند و با دیدن خطوط عمود بر هم سلولهای متفاوتی حساسیت نشان میدهند. هابل و ویزل دریافتند که این سلولها به شکل ستونی و خیلی منظم در کنار همدیگر قرار گرفتهاند و حاصل همکاری آنها با هم این است که ما میتوانیم ادراک تصویری خوبی از محیط پیرامون داشته باشیم. اساس کار شبکه عصبی کانولوشن نیز مانند قشر بینایی مغز ماست! در حقیقت در یک CNN، لایههای مختلفی وجود دارند که هر یک لایه مخصوص شناسایی موارد خاصی است. در نهایت نیز خروجی مدل ادراک تصویری کامل است.
ساختار شبکه عصبی پیچشی چیست؟
همانطور که اشاره کردیم، در یک شبکه عصبی پیچشی، کامپیوتر یک تصویر را به عنوان ورودی میگیرد؛ سپس این تصویر وارد یک شبکهی پیچیده با چندین لایهی پیچشی و غیر خطی میشود. در هر یک از این لایهها، عملیاتهایی انجام میشود و در انتها بر روی خروجی، یک کلاس یا درصد وقوع چند کلاس مختلف نشان داده میشود. قسمت سخت ماجرا، لایههای میانی و نحوه عملکرد آنهاست! در ادامه به بررسی مهمترین لایهها میپردازیم.

لایه اول در شبکه عصبی کانولوشن | مفاهیم ریاضیاتی
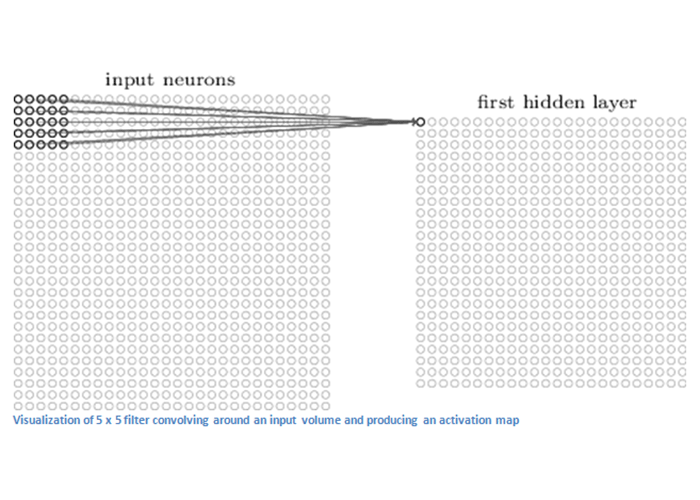
لایه اول در یک شبکه عصبی پیچشی، همیشه یک لایهی کانولوشنال است. همانطور که قبلا اشاره کردیم، ورودی این لایه یک آرایه از اعداد است. لایه اول در شبکه عصبی مانند یک چراغ قوه کار میکند! در یک اتاق تاریک، چراغ قوهای را تصور کنید که بر گوشهی بالا و سمت چپ تصویر میاندازیم و محدودهای از تصویر روشن میشود و آن قسمت را میبینیم. سپس چراغ قوه را بر روی قسمتهای دیگر تصویر میگیریم تا کمکم کل تصویر را ببینیم. حال بیایید داستانهایی که تعریف کردیم را به زبان یادگیری ماشین، بازگو کنیم! در شبکه عصبی کانولوشن، به این چراغ قوه، فیلتر (filter) (یا نورون یا کرنل) میگوییم. آن قسمتی از تصویر که چراغ قوه به آن نور میتاباند، محدود پذیرش (receptive field) نام دارد. لازم به ذکر است، فیلترها نیز خود آرایههایی از اعداد هستند. به اعداد موجود در فیلتر، وزن (weight) یا پارامتر (parameter) گفته میشود. لازم به ذکر است که عمق این فیلتر باید با عمق تصویر برابر باشد. مثلا اگر تصویر یک آرایه عددی ۵*۵*۳ (عمق ۳) است، فیلتر نیز باید چنین باشد. فیلتر در هر نگاه، یک قسمت از تصویر را میبیند. سپس بر روی تصویر حرکت میکند تا قسمتهای دیگر را هم اسکن کند. به این حرکت فیلتر بر روی تصویر، پیچیدن (convolve) میگویند. همین طور که فیلتر از تصویر عبور میکند، اعداد موجود در فیلتر با آرایه عددی پیکسلهای تصویر ضرب میشود. در نهایت نیز تمام حاصل ضربها با یکدیگر جمع میشوند و به یک عدد میرسیم. فرض کنید میخواهیم یک تصویر با ابعاد ۳۲*۳۲*۳ را با استفاده از یک فیلتر ۵*۵*۳ ببینیم. این فیلتر با عملیاتی که توضیح دادیم در نهایت یک آرایه عددی با ابعاد ۲۸*۲۸*۱ تولید میکند (علت ۲۸*۲۸ بودن آن است که به ۷۸۴ حالت میتوان یک تصویر ۳۲*۳۲ را با استفاده از فیلتر ۵*۵ دید). به ماتریس ۲۸*۲۸*۱ که در نهایت به دست میآید نقشه فعالسازی (activation map) یا نقشه ویژگی (feature map) میگوییم. اگر به جای یک فیلتر، از دو فیلتر استفاده کنیم، در نهایت به یک ماتریس با ابعاد ۲۸*۲۸*۲ میرسیم. این کار میتواند دقت ما را در ابعاد بالاتر افزایش دهد.
لایه اول در شبکه عصبی کانولوشن | مفاهیم کاربردی
بیایید نگاهی از بالا بیندازیم و ببینیم شبکه عصبی پیچشی (CNN) واقعا چه کار میکند. هر یک از فیلترهایی را که در قسمت قبلی به آنها اشاره کردیم، میتوان به عنوان یک شناساگر ویژگی (feature identifier) در نظر گرفت. منظور از ویژگی (feature) در این جا، چیزهایی مانند خط صاف، یک رنگ ساده یا یک انحناست. فرض کنیم فیلتر اول، یک فیلتر با ابعاد ۷*۷*۳ و یک شناساگر انحناست. این فیلتر در حقیقت یک ماتریس عددی مانند تصویر زیر است که درایههای این ماتریس در محلهایی که انحنا وجود دارد، مقادیر عددی بالاتری دارند. حال این فیلتر را بر روی قسمتی از تصویر مد نظرمان قرار میدهیم. پس از آن مانند تصویر زیر، درایه به درایه اعداد موجود در خانهها را با هم ضرب و حاصل ضربها را با یکدیگر جمع میکنیم.
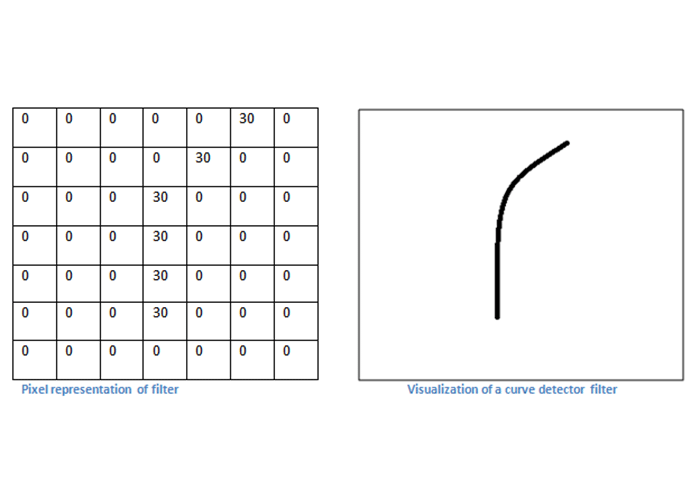
همانطور که مشاهده میکنید، حاصل بهدستآمده، یک عدد بزرگ است. بزرگ بودن این عدد نشانگر آن است که در این ناحیه یک انحنا مانند انحنای فیلتر وجود دارد.
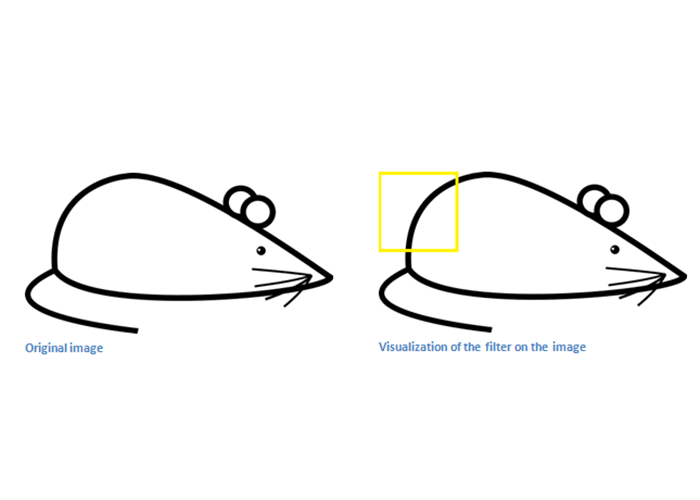
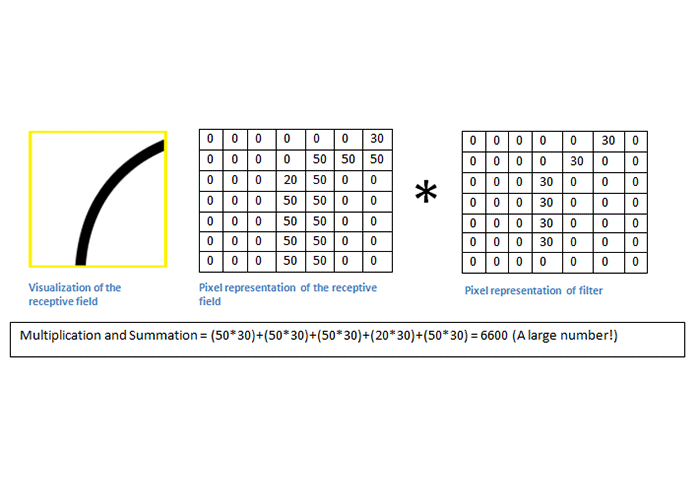
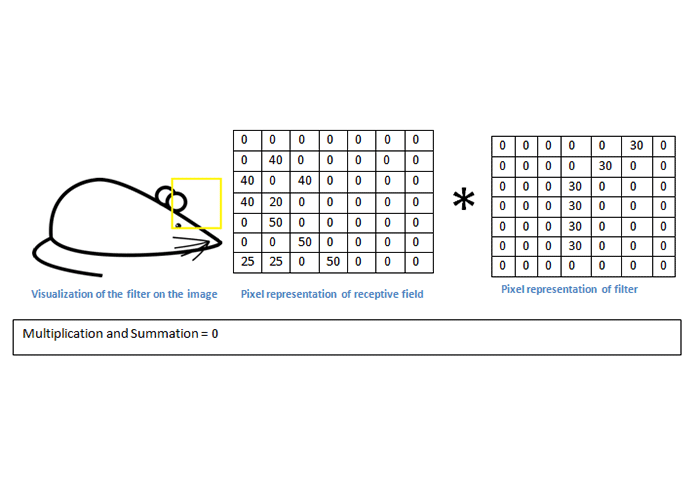
در تصویر زیر، حاصل ضرب عدد کوچکی میشود؛ علت آن است که فیلتر با تصویر ورودی تطابق ندارد. همانطور که اشاره کردیم، ما در پی آن هستیم که یک نقشه فعالسازی به دست بیاوریم؛ یعنی یک آرایه از اعداد با ابعاد ۲۶*۲۶*۱ (فرض کنیم فقط از یک فیلتر شناساگر منحنی استفاده کنیم). قسمت بالا و سمت چپ این نقشه فعالسازی، مقدار ۶۶۰ را خواهد داشت. این عدد بزرگ نشاندهندهی آن است که در ناحیهی خاصی از تصویر، با احتمال زیاد یک منحنی وجود دارد. توجه کنید که ما در این جا تنها از یک فیلتر استفاده کردیم. برای آن که اطلاعات بیشتری از تصویر استخراج کنیم، نیاز داریم تا از فیلترهای بیشتری استفاده کنیم؛ استفاده از فیلترهای بیشتر یعنی ابعاد بالاتر.
لایههای عمیقتر شبکه عصبی کانولوشن
در یک شبکه عصبی، علاوه بر لایهی توضیح داده شده، لایههای دیگری نیز وجود دارند. این لایهها وظایف و عملکردهای گوناگونی دارند. به طور کلی، لایههای داخلی، مسئول نگهداری و حفظ ابعاد و امور غیرخطی هستند. آخرین لایه در شبکه عصبی کانولوشن نیز از اهمیت خاصی برخوردار است.
لایه آخر در شبکه عصبی پیچشی
در لایه آخر یک شبکه عصبی کانولوشن، خروجی سایر لایهها، به عنوان ورودی دریافت میشود. خروجی لایه آخر هم یک بردار N بعدی است. N تعداد کلاسهای موجود است. به عنوان مثال اگر شبکهی شما، یک شبکه برای شناسایی اعداد باشد، تعداد کلاسها دهتاست؛ چون ده رقم داریم. در بردار N بعدی، هر مولفه، احتمال وقوع یک کلاس را نشان میدهد. کاری که لایهی آخر یک شبکه عصبی کانولوشن میکند آن است که به ویژگیهای لایههای سطح بالا نگاه میکند و میزان مطابقت این ویژگیها را با هر کلاس مقایسه میکند؛ هر چه این مطابقت بیشتر باشد، احتمال وقوع آن کلاس، بالاتر معرفی میشود.
نحوه عملکرد شبکه عصبی کانولوشن چیست؟
تا به این جا اطلاعات زیادی درباره شبکه عصبی پیچشی به دست آوردید؛ اما احتمالا هنوز هم سوالات فراوانی دارید و سوالات جدید نیز در ذهنتان شکل گرفته است. سوالاتی از این قبیل که فیلترها چگونه ساخته میشوند یا …. کامپیوتر طی یک فرایند آموزش (training) میتواند مقادیر مناسب را به فیلترها تخصیص دهد. این فرایند backpropagation نام دارد. ما انسانها زمانی که متولد شدیم، هیچ درکی از اشیای پیرامونمان نداشتیم. به مرور زمان، اشیای مختلف را دیدیم و اطرافیان، نام آن اشیا را به ما گفتند و یاد گرفتیم. کامپیوترها نیز عملکردی مشابه دارند؛ به این معنا که در ابتدای کار، اعداد موجود در ماتریس فیلتر، رندم و تصادفی هستند. به مرور زمان و با نشان دادن تصاویر مختلف به کامپیوتر، اعداد موجود در فیلتر تصحیح میشوند تا به یک عملکرد قابل قبول برسند.
تست شبکه عصبی CNN
پس از آن که مدل ما نهایی و آمده شد، وقت تست کردن فرا میرسد. برای تست مدل از تعدادی تصویر که میدانیم محتویات آن چیست، استفاده میشود. تصویر را به ورودی مدل میدهیم تا خروجی را به ما نشان دهد؛ سپس خروجی را بررسی میکنیم تا ببینیم درست عمل شده است یا نه.
شرکتها چگونه از شبکه عصبی کانولوشن استفاده میکنند؟
امروزه، شرکتهایی که دادههای بیشتری جمعآوری کنند، مسلما بر رقبای خود پیروز میشوند. دیتا، طلای دنیای نوین است! هر چقدر که به یک مدل یادگیری عمیق دیتای بیشتری وارد کنیم، مدل تعداد دفعات بیشتری اصلاح میشود و در نهایت کارایی بهتری خواهد داشت. شرکتهایی مانند فیسبوک (اینستاگرام) و پینترست میتوانند از حجم عظیم دیتای تصویری استفاده کنند تا مدلهای بینظیری بسازند.
در این مقاله سعی کردیم یک آشنایی مقدماتی با شبکه عصبی کانولوشن ایجاد کنیم. این موضوع، بسیار گسترده است و میتوانید برای کسب اطلاعات بیشتر سایر مقالات فنولوژی را مطالعه کنید.
منبع: GITHUB





عالی بود واقعا. ترجمهی خیلی روان و مناسبی داشت.
ممنون از توجه شما دوست عزیز
لذت بردم
خوشحالم که مفید بوده
سلام. واقعا ممنونم از مطالب خوبتون . بسیار کاربردی هستش و من خیلی از این مطالب بهره بردم .
سلام دوست عزیز
خوشحالیم که مفید واقع شده
سلام
خیلی عالی بود مرسی
سلام نیمای عزیز
ممنون از توجه شما
عالی نوشتید خیلی ساده با یه مثال بیان کردید .عالی بود
ممنون و موفق باشید
ممنون از توجه و لطف شما
واقعا عالی و قابل فهم بود
مرسی از نظر شما
روان و سلیس بیان شده بود با کمال تشکر
سپاسگزاریم از توجه شما
آفرین پسر،
توضیح روان و قابل فهمی بود.
تشکر مهندس
ممنون از شما
سلام.
خیلی ممنون.
عالی بود👏👏👏.
امکانش هست
سلام
ممنون از شما
با سلام ممنونم از بیان ساده و روانتون. بسیار عالی بود
ممنون از سایت فنولوژی خیلی چیز ها ازش یادگرفتم
سلام استاد
در مورد یک پروژه میخوام با شما مشورت کنیم
میتونید یه ایمیل برام بفرستید تا در این مورد صحبت کنیم؟
ممنون
بسیار عالی و قابل فهم توضیح دادین خیلی خیلی ممنونم انشااله همیشه موفق و پاینده باشید